
Runtime and GPU support¶
The training/scoring of Keras models can be run on either a CPU, or one or more GPUs. Training on GPUs is usually much faster, especially when images are involved.
Code environment¶
Deep Learning in DSS uses specific Python libraries (such as Keras and TensorFlow) that are not shipped with the DSS built-in Python environment.
Therefore, before training your first deep learning model, you must create a code environment with the required packages. See Code environments for more information about code environments.
To help you, you can simply click “Add additional packages” in the “Packages to install” section of the code environment.
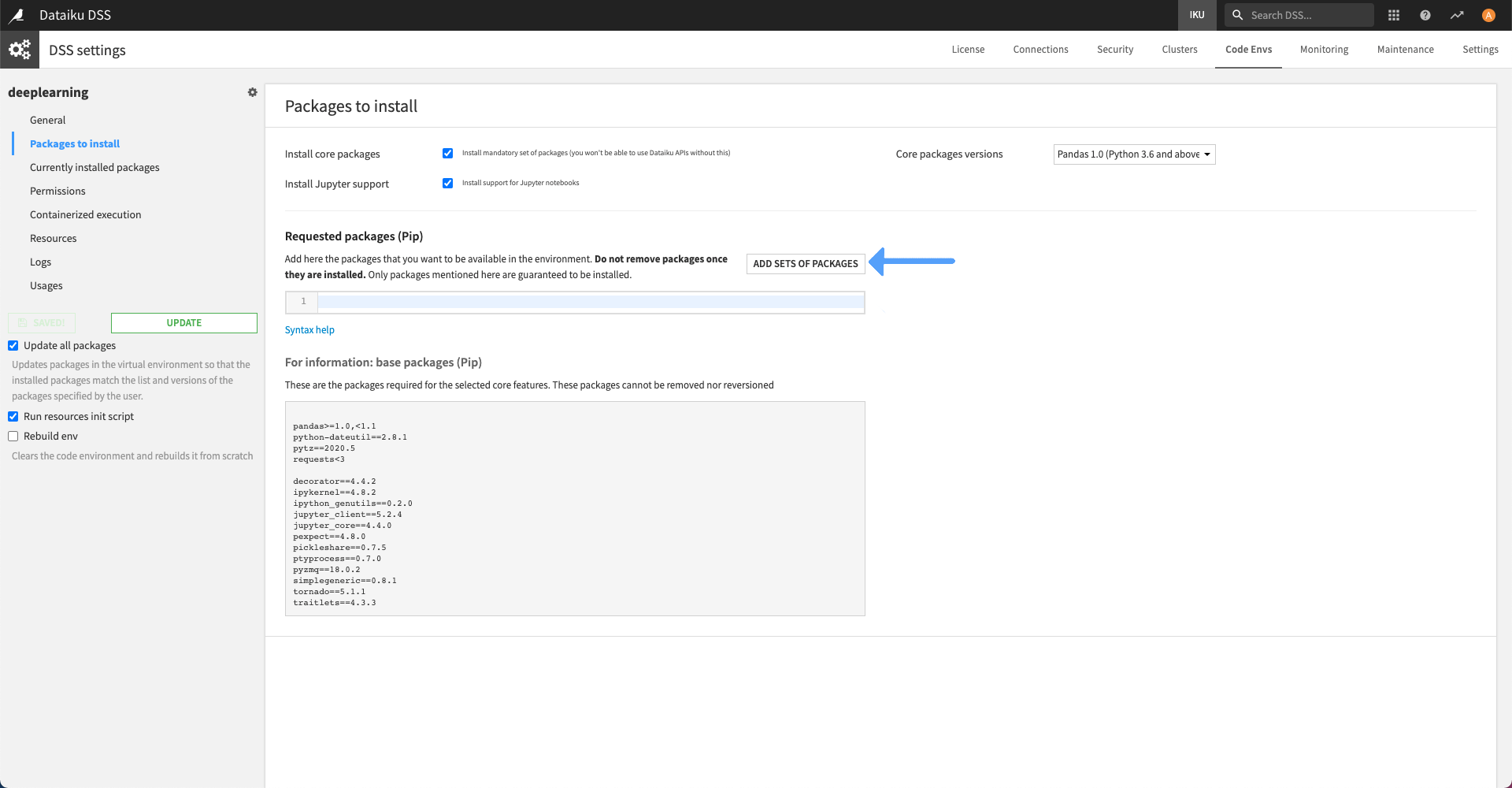
There you can select the “Visual Deep Learning: Tensorflow. CPU, and GPU with CUDA11.2 + cuDNN 8.1” package preset.
Once the proper environment is set-up, you can create a Deep Learning model. DSS will look for an environment that has the required packages and select it by default. You can select a different code environment at your own risk.
Selection of GPU¶
If your DSS instance has access to any GPU resource(s), you can opt to train the model on a selection of these when you click ‘TRAIN’.
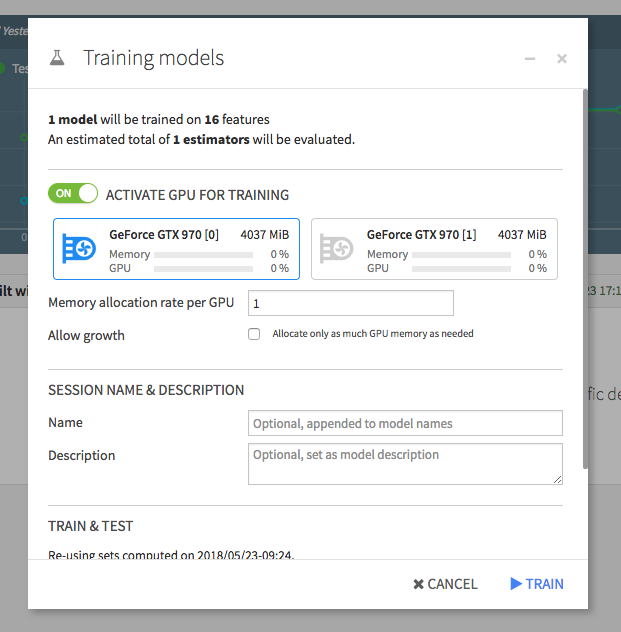
When you deploy a scoring or evaluation recipe, you can also choose to score or evaluate using GPU(s), configured in the recipe settings.
If a model trained on a GPU code environment is deployed as a service endpoint on an API node, the endpoint will require access to a GPU on the API node, and will automatically use GPU resources.
We enforce ‘allow growth’ on deep learning models ran on API nodes to ensure they only allocate the required memory (see TensorFlow documentation).
Using multiple GPUs for training¶
If you have access to GPU(s) on your DSS instance server or on any available containers, you can use them to speed up training. You will not need to change your model architecture to allow you to use GPUs, as DSS will manage this.
DSS will replicate the model on each GPU, then split each batch equally between GPUs. During the backwards pass, gradients computed on each GPU are summed. This is made possible thanks to TensorFlow’s MirroredStrategy.
This means that on each GPU, the actual batch_size will be batch_size / n_gpus. Therefore you should use a batch_size that is a multiple of the number of GPUs.
Note: To compare the speed of two trainings, you should always compare trainings with the same per GPU batch_size, i.e. if the first training is run on one GPU with a batch_size of 32, and the second on two GPUs, the batch_size should be 64.