
Advanced topics¶
Start with weights from a previously trained model¶
You can initialize a model training with weights from another model for transfer learning & fine-tuning.
To do so, Keras provides the load_model and load_weights methods to retrieve previously saved models or weights.
DSS provides functions to retrieve the location of models, either from a ML task or a saved model:
# in dataiku.doctor.deep_learning.load_model
get_keras_model_from_trained_model(session_id=None, analysis_id=None, mltask_id=None)
get_keras_model_location_from_trained_model(session_id=None, analysis_id=None, mltask_id=None)
get_keras_model_from_saved_model(saved_model_id)
get_keras_model_location_from_saved_model(saved_model_id)
How is the model trained?¶
Whether you use Standard or Advanced mode, DSS trains the model using Sequence objects and the fit method.
This preprocesses the data in batches and not all at once to prevent using too much memory, in particular for texts and images, which are memory-intensive.
DSS will preprocess data and produce those sequences: train and validation (what we usually call test is called validation in Keras terminology), depending on the size of each batch, and call fit_generator. You can customize how the process is done.
Advanced training mode¶
The Advanced mode for training (accessible by clicking on the top right of the analysis) allows you to modify the data, preprocessed by DSS that will be sent to the model, and to customize the parameters of the call to fit_generator. In particular, the two main use cases of using the Advanced mode are:
data augmentation
using custom Callbacks
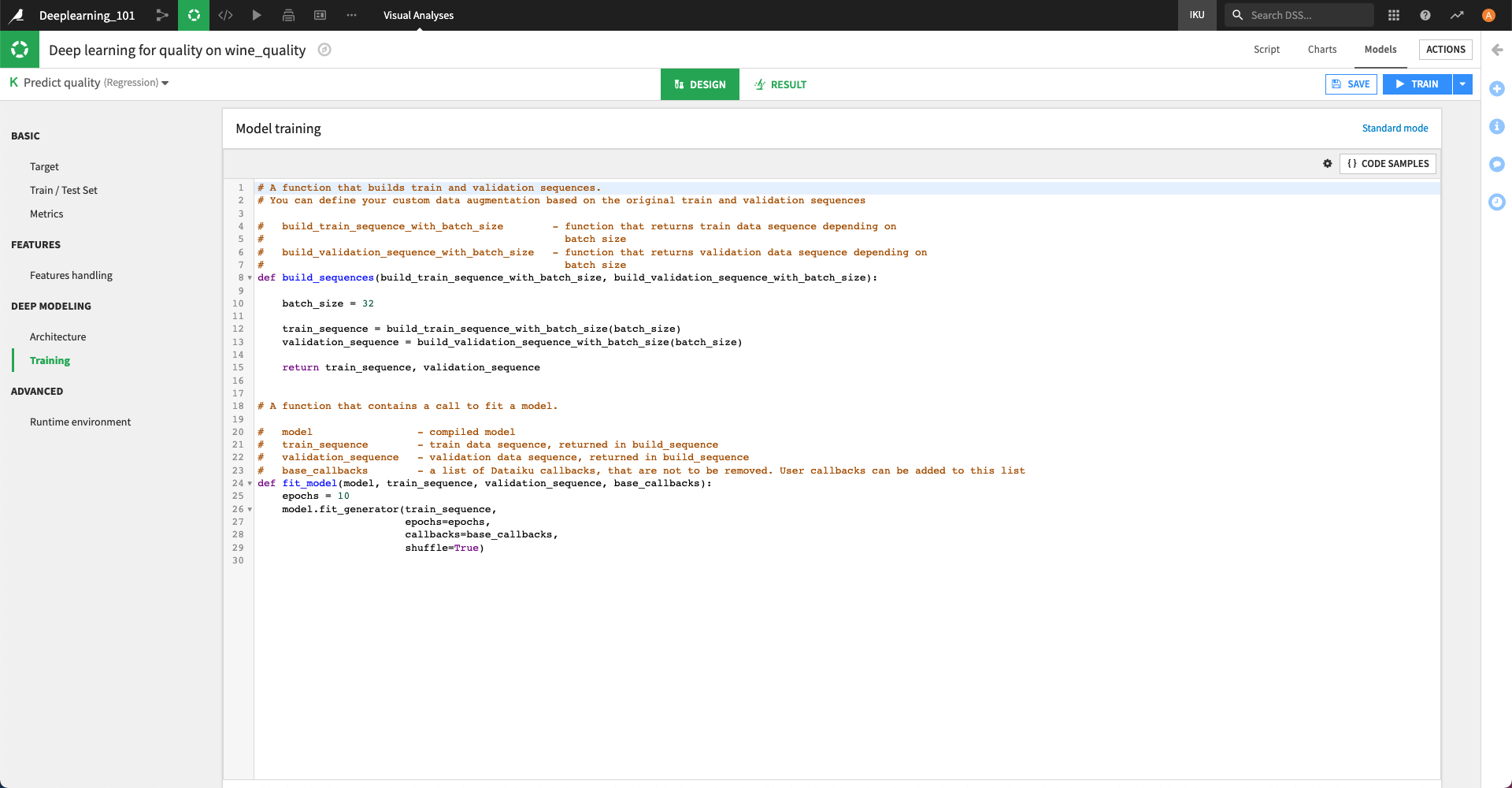
You need to fill two methods
Build sequence¶
The method build_sequence should return the sequences that will be used to train the model. To do so, you have access to helpers build_train_sequence_with_batch_size and build_validation_sequence_with_batch_size, which are functions that return sequences depending on a batch_size.
Then you can modify at will these sequences before training. In particular, you may want to perform some data augmentation. DSS provides a helper to do so, which looks like:
from dataiku.doctor.deep_learning.sequences import DataAugmentationSequence
from tensorflow.keras.preprocessing.image import ImageDataGenerator
original_batch_size = 8
train_sequence = build_train_sequence_with_batch_size(original_batch_size)
augmentator = ImageDataGenerator(
zoom_range=0.2,
shear_range=0.5,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True
)
augmented_sequence = DataAugmentationSequence(train_sequence, "image_name_preprocessed", augmentator, n_augmentation=3)
where:
image_name_preprocessed is the name of the input to augment
n_augmentation is the number of time the sequence is augmented
ImageDataGenerator is a helper provided by Keras to perform data augmentation on images.
For custom augmentation, you can provide your own instance of a class implementing a random_transform method with the following signature:
def random_transform(x, seed=None):
# returns a numpy array with the same shape as x
When you use data augmentation, you need to be aware that the actual batch size of its augmented sequence will be original_batch_size * n_augmentation, therefore you may want to provide a smaller original_batch_size.
Fit model¶
The method fit_model allows you to define custom Keras callbacks.
As per Keras documentation,
A callback is a set of functions to be applied at given stages of the training procedure. You can use callbacks to get a view on internal states and statistics of the model during training
DSS builds a list of base_callbacks (to compute metrics, interrupt model if requested in the UI …) that must be added in the call to fit_generator. Then, you are free to add any custom callback to this list.
Usage of metrics in Callbacks¶
Many built-in (or custom) Callbacks from Keras require a metric to monitor. Their behavior will depend on the value of this metric. For example, the Early Stopping callback will stop the model training prior to completing all planned epochs if the tracked metric is no longer improving.
Usually, you define the metrics you want to track in the metrics parameter of the compile function. Then you can retrieve them via the callbacks. DSS also computes its own metrics through a base callback depending on the prediction type:
Regression:
‘EVS’
‘MAPE’
‘MAE’
‘MSE’
‘RMSE’
‘RMSLE’
‘R2 Score’
‘Custom Score’
Binary Classification
‘Accuracy’
‘Precision’
‘Recall’
‘F1 Score’
‘Cost Matrix Gain’
‘Log Loss’
‘Cumulative Lift’
‘ROC AUC’
‘Average Precision’
‘Custom score’
Multiclass Classification
‘Accuracy’
‘Precision’
‘Recall’
‘F1 Score’
‘Log Loss’
‘ROC AUC’
‘Average Precision’
‘Custom score’
As DSS tracks metrics on the ‘Test’ set, you need to prepend ‘Test ‘ to the name of the metric to have the proper name.
Warning
As they are computed in a base callback, if you want to use them, you need to put your custom callback after the list of base_callbacks provided by DSS, in the list that you will pass to fit_generator.
For example, in a binary classification problem, if you want to introduce an early stopping callback monitoring ROC AUC, you can add the following callback to its list
from tensorflow.keras.callbacks import EarlyStopping
early_stopping_callback = EarlyStopping(monitor="Test ROC AUC",
mode="max",
min_delta=0,
patience=2)
DSS also provides a helper to retrieve in the code the name of metric that is used for the optimization of the model, along with the info on whether it is a loss (and lower is better) or a score (greater is better). You can access those variables with
from dataiku.doctor.deep_learning.shared_variables import get_variable
metric_to_monitor = get_variable("DKU_MODEL_METRIC")
greater_is_better = get_variable("DKU_MODEL_METRIC_GREATER_IS_BETTER")
and the previous early stopping callback becomes
from dataiku.doctor.deep_learning.shared_variables import get_variable
from tensorflow.keras.callbacks import EarlyStopping
metric_to_monitor = get_variable("DKU_MODEL_METRIC")
greater_is_better = get_variable("DKU_MODEL_METRIC_GREATER_IS_BETTER")
early_stopping_callback = EarlyStopping(monitor=metric_to_monitor,
mode="max" if greater_is_better else "min",
min_delta=0,
patience=2)