
Managing dates¶
Working with dates in Preparation¶
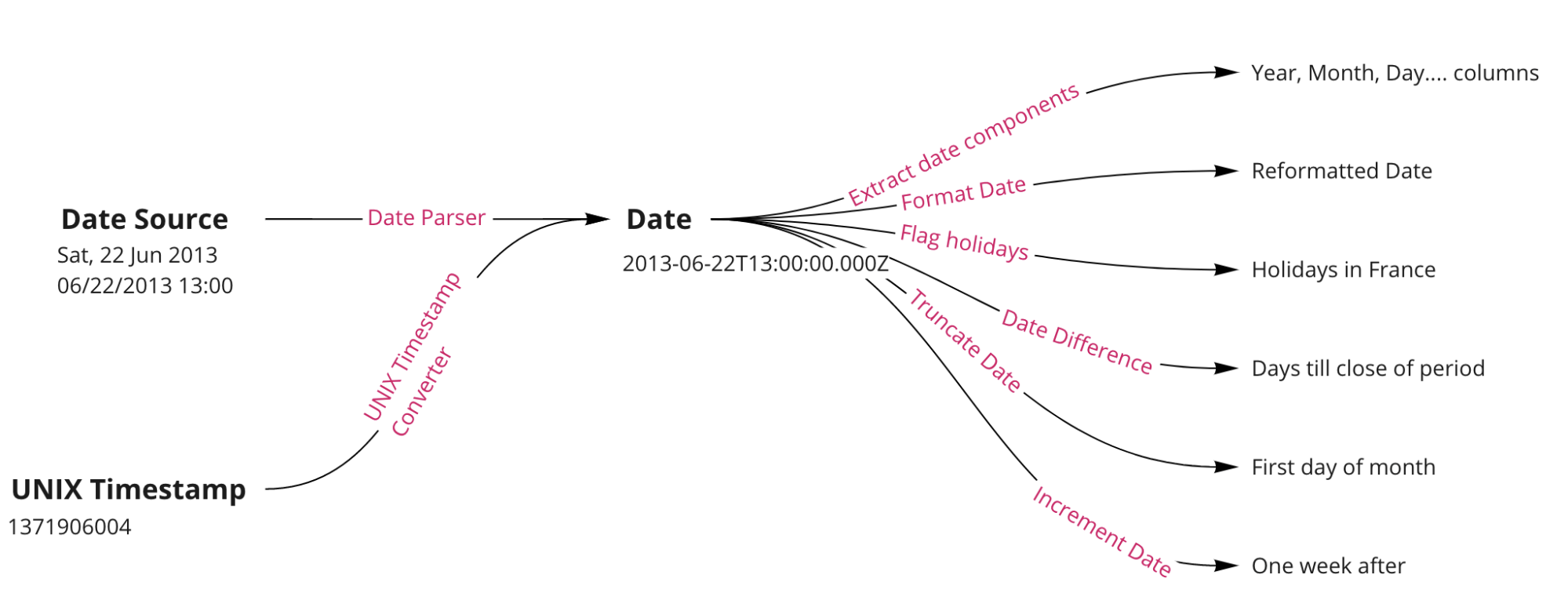
Data Preparation provides several components for easy management, transformation and normalization of dates.
Meanings and types¶
The Datetime with zone meaning is the main meaning in Dataiku DSS used for representing dates in a non-ambiguous format. Two standard date formats, both including timezone information, are recognized as valid:
ISO-8601 with timezone indicator: for example
2013-05-30T15:16:13.764Zor2013-05-30T15:16:13.764+0200RFC 822: for example
Tue, 22 Jan 2013 12:14:33 GMT
Both these formats include timezone information and are therefore non-ambiguous. Internally, the Datetime with zone type handles all dates in UTC.
In addition to Datetime with zone, DSS offers 2 temporal data types:
Date only represents a date without any time information. It accepts ISO-8601 dates like
2013-05-30Datetime no zone represents a wall-clock time on a given day, without any time zone indication. It accepts values like
2013-05-30 15:16:13.764
Dates stored in all other date formats need to be parsed into one of the temporal data types in order to leverage the date manipulation and transformation components described below.
Any columns that are recognized as likely to contain dates but which have yet to be converted into either valid format will be automatically given the meaning ‘Date (unparsed)’. Only columns recognized as having valid date formats can be stored using the ‘datetime with zone’, ‘date only’ or ‘datetime no zone’ storage types. Dataiku DSS performs all computations on ‘datetime with zone’ columns in UTC timezone for the server’s locale, unless otherwise specified.
Parsing Dates¶
Parsing a date column will convert a column that contains a date written in non-ISO-8601 or non-RFC-822 format into a standard, non-ambiguous format. Once parsed, Dataiku DSS will consistently recognize and use a date column as such. The output can be chosen to be any of the 3 data types handled by DSS: datetime with tz, date only or datetime no tz.
The asDatetimeTz function in Dataiku DSS can be used to parse dates into an acceptable format as can the features
described below. Its counterparts for the other temporal data types are asDateOnly and asDatetimeNoTz.
Smart Date Parser¶
The ‘Smart Date’ parser detects probable formats in which an unparsed date column is written and assists in generating the correct format for use in the date parsing processor. There are two ways to parse a column into a date; both will open the Smart Date parser:
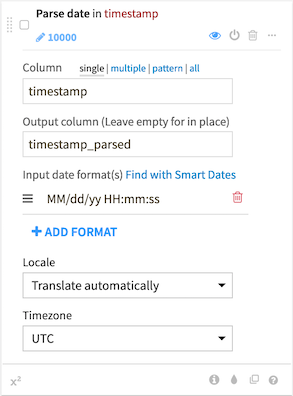
Select ‘Parse date…’ from the dropdown menu that appears upon hovering the column name of a column recognized as “Date (unparsed).”
Open the Processor Library (“+ADD A NEW STEP”), select the “Parse to standard date format” processor under the “Dates” category, input the column name then click “Find with Smart Dates.”
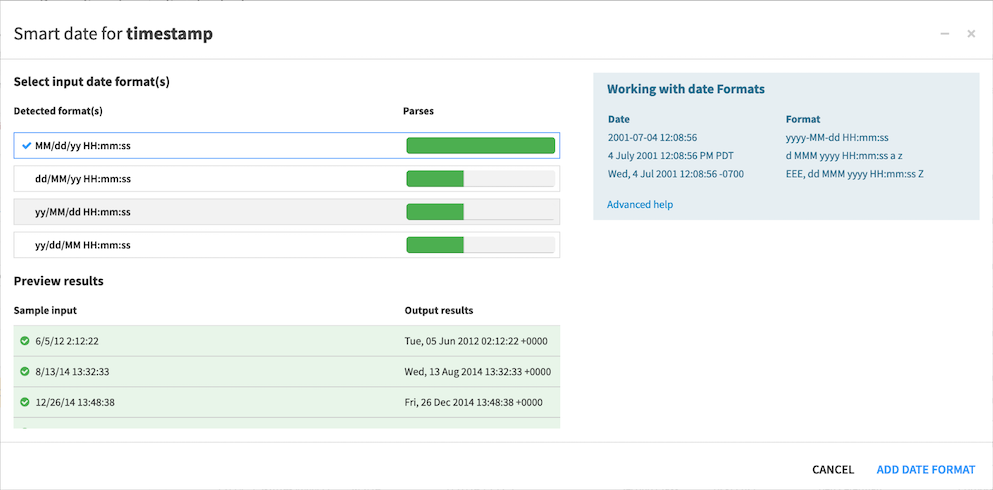
The Smart Date parser displays a list of probable date formats. Select the one that best fits the format of your data and it will then populate the ‘inputs date format(s)’ section of the parse date processor.
On occasion, the Smart Date parser cannot automatically recognize the format of a date column. In this case, you can input a custom format at the bottom of the list of detected formats. As you type your custom format using the Java DateFormat syntax, (https://docs.oracle.com/javase/7/docs/api/java/text/SimpleDateFormat.html), Dataiku DSS checks the syntax in real-time, indicates the extent to which the custom format fully parses the source data or not, and displays the result of the parsing in real-time.
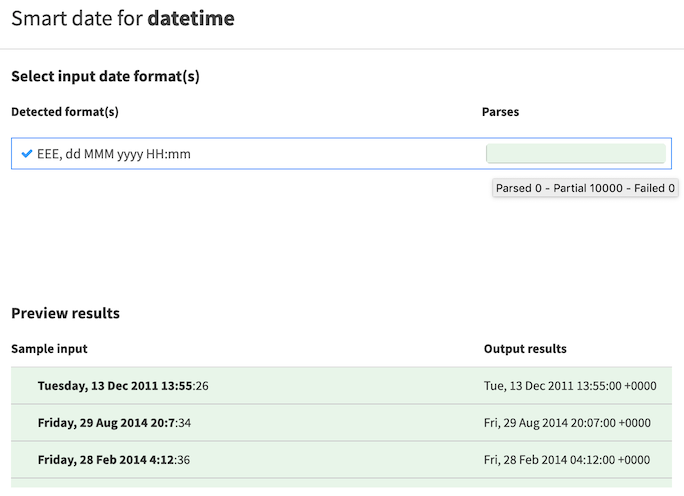
Parse date processor¶
The parse date processor will convert columns in your dataset to a valid date format for use in DSS. The Smart Date parser can assist in identifying the correct date format(s) for dates as they are stored in your dataset.
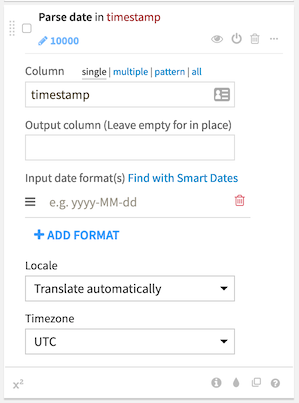
Internationalized parsing¶
Some dates include international formats like month names or day names.
By default, the Date Parser automatically parses these elements in both French and English. You can also force a specific locale for these internationalized elements.
Timezones¶
Any date recognized as valid by Dataiku DSS includes complete timezone information so that dates remain unambiguous.
Some date formats natively include timezone information like +0200, CST, UTC, etc. These are denoted by the Z character
in the date parsing pattern. 2013/04/17 13:23:32 +0400 will be parsed to 2020-04-17T09:23:32.000Z using
‘yyyy/MM/dd HH:mm:ss Z’ as a conversion pattern.
However, most formats do not include timezone information. For these formats, the date parsing processor needs to know in which timezone this value was recorded. There are three ways to determine the timezone for a given row:
Using a static value (like “UTC” or “Europe/Paris”) : you indicate that all your rows are at a given timezone, and Date parser will use this. This is useful for example, for timestamps in server log files, where all servers are at the same time zone.
Using a timezone column. If your row contains a column with timezone information, Date parser can use it directly. This allows you to have a different timezone per row. You need to configure which column contains the timezone information.
Note
If for a given record, the timezone information is invalid, the Date parser does not output a date for this row
Using an IP address column. If your row contains an IP address, and you know that the timezone of the row is the timezone of the IP address (for example, a client-generated timestamp in a web browsing log). The Date parser will automatically geolocate this IP address and use the timezone of the detected location. You need to configure which column contains the IP address.
Note
If the Date Parser cannot geolocate the IP, it does not output a date for this row
Converting from a UNIX timestamp¶
Columns that contain a UNIX timestamp are handled separately. You do not parse them using the Smart Date / Date parse processor combination. Use the dedicated “Convert UNIX timestamp to a date’ processor instead. UNIX timestamps are always expressed in UTC.
UNIX timestamps can come into two variants: in seconds since Epoch (i.e. January 1st 1970) or in milliseconds since Epoch.
You need to indicate which format your column is in.
Using dates¶
Once you have a column in proper non ambiguous format, with the “Datetime with zone”, “Date only” or “Datetime no zone” type, you can perform various operations on this column:
Extract some components of the date (year, month, day, week, day of week, ..) into separate columns
Reformat the date into another format
Manipulate your date field(s) by incrementing, truncating, or finding the difference between two date columns
Flag / filter rows based on a variety of time divisions
Extracting date components¶
This processor allows you to easily extract components from the date into separate columns. For example, you could create a column with the day of the week for each row. The day of the week is generally a very good feature for machine learning.
The components that can be extracted from a “Datetime with zone” or a “Datetime no zone” column are:
Year
Month (01 = January, 12 = December)
Day
Week of year
Week year
Day of week (1 = Monday, 7 = Sunday)
Hour
Minutes
Seconds
Milliseconds
For a “Date only” column, hours, minutes, seconds and milliseconds are not possible.
Additional date components are available using the datePart function in a Formula processor (see Formula language)
Timezones handling¶
All computations on parsed date columns are performed in UTC. However, it is often useful to extract information from a column in a different timezone.
For example, imagine that you are processing web log files containing page events coming from all around the world. The Datetime with zone column that indicates the timestamp of the event is always aligned on the UTC timezone. What we want to know is at what time of the day the most events happen. However, we want this information in the local timezone of the client that generated this event. For example, we might want to know the proportion of events that happen in the morning for the client rather than for the server.
To help you with that, while extracting components, Dataiku DSS can “realign” them on a different timezone.
Like for the Date Parser, this timezone can be specified using 3 different ways:
Using a static value (like “UTC” or “Europe/Paris”). All components for all rows will be output on this timezone.
Using a timezone column. If your row contains a column with timezone information, the extractor can use it directly. This allows you to have a different timezone per row. You need to configure which column contains the timezone information.
Using an IP address column. If your row contains an IP address, and you know that the timezone of the row is the timezone of the IP address (for example, a client-generated timestamp in a web browsing log). The extractor will automatically geolocate this IP address and use the timezone of the detected location. You need to configure which column contains the IP address.i
Example:
We have a web log file with a Date, in UTC, which is the date of the hit on the server, and with the IP of the client
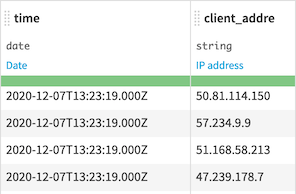
If we extract the day and the hour using UTC timezone, we get them for the server UTC timezone. This does not tell us at what time of their days customers come on the website
If we use the IP column as timezone source, Data Science Studio geolocates each IP, and uses the timezone of the IP to automatically translate the date components in the local timezone.
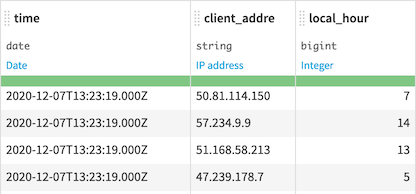
Some hits at 11pm UTC in France are actually at 1am local time (GMT + 2 due to DST)
Some hits at 12am UTC in the US are actually at 8pm local time (GMT - 4 due to DST)
Reformating dates¶
The ‘Format date’ processor allows you to recreate a date column as a “human-readable” string. Like the date components extractor described above, the date formatter allows you to realign dates on a local timezone. The date formatter can either be opened by creating a new ‘format date’ processor or by selecting the appropriate action in the column dropdown.
The format of the Date Formatter must be specified using the Java DateFormat specification.
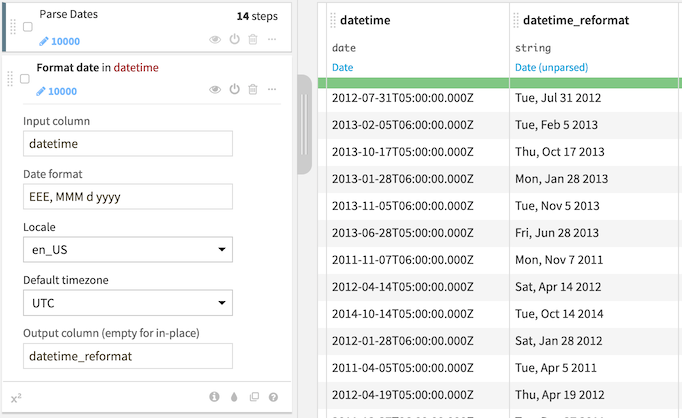
The formatter can be outputted dates in English or French.
Performing date calculations¶
Several processors facilitate performing calculations on date columns. It is possible to use a processor to increment
a date column by a specified unit of time, to truncate a date column by a specified unit of time, and to calculate
the difference between two date columns in terms of the specified time. The inc, trunc, and diff functions
of the Dataiku DSS formula language will perform the same calculations as well.
Filtering or flagging rows using dates¶
Several capabilities exist to help you create a variety of different types of date filters which you can apply to the preview of your data or as a script step–static ranges, relative ranges, and filters on date components–without writing a complex formula. Open the filter pop-up from the dropdown menu of any parsed date column, set your range, and click on ‘Apply as step’ to add that filter as a script step:
A static date range: supports a closed range (2020-10-01 to 2020-10-05) or an open one (after 2020-10-01). Time zones are supported.
A relative date range: define a moving date filter with which to filter your data. Each period is a calendar period and calculated at each run relative to the time on the server.
A range based on date part: filter by year, quarter, month, etc…
For more information, refer to the documentation about filtering and flagging processors