
Partitioned SQL datasets¶
Partitioning SQL table datasets¶
Datasets based on SQL tables support partitioning based on the values of specified columns: the partitioning columns must be part of the schema of the table.
External SQL table datasets¶
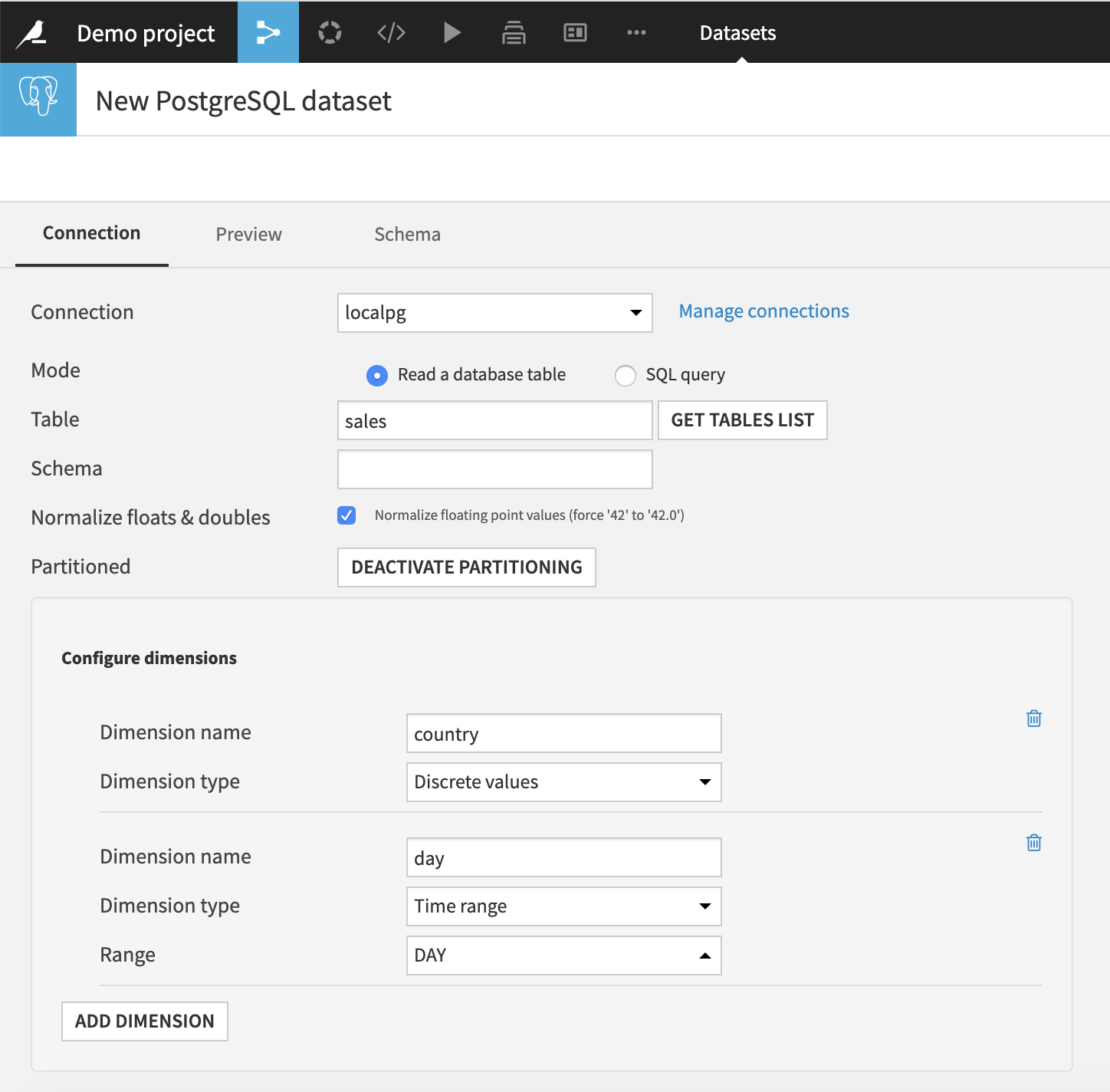
For an external SQL table dataset, you must configure:
Which columns provides the partitioning values. For example “country” or “day”.
- The type and parameters of each partitioning dimension. For example:
Discrete values
Time with period DAY
Dataiku DSS can automatically list the available partitions by enumerating the values of the provided columns. In some cases, enumerating the values can be prohibitively costly. This is particularly the case when working on a non-column-oriented database without index on a partitioning column. In that case, you may specify an explicit, comma-separated, list of available partitions. Dataiku DSS will use this list whenever it needs to list the partitions of the dataset. Each element of the list can be a partition identifier or a partition range specification. For more information on partition identifiers, see Partition identifiers.
If your database engine natively supports partitioning and the external table uses it, Dataiku DSS suggests to use the native partitioning support. Checking this option, will make listing and removing partitions much more efficient. It might also make getting the records of a partition more efficient.
In the dataset edition screen, Dataiku DSS automatically selects an arbitrary partition to preview.
Managed SQL table datasets¶
For partitioning, Managed SQL table datasets behave like external SQL table datasets.
Note
In a managed SQL table dataset, you define the schema of the table yourself. Don’t forget that you MUST have the partitioning column in the table schema. If you don’t have it, testing the dataset will fail.
Partitioning SQL query datasets¶
SQL query datasets provide additional flexibility when it comes to partitioning (with a more complex setup).
To summarize:
The SQL query must use specific patterns to replace the requested values of the partition
You must provide a way to list the partitions
You must provide a partition identifier that will be used by Dataiku DSS to perform the preview in the dataset screen.
Let’s take an example. If we have the following database schema:
event {
geography_id integer;
type string;
user_id integer;
timestamp integer;
}
geography {
id integer
continent string,
country string,
region string,
city string
}
user {
id integer;
sex varchar(1);
}
We want to create a dataset with the following data:
event_type
user_sex
timestamp
city
And we want that dataset to be partitioned by day and country. We cannot do that directly using SQL table datasets, and need to use SQL query datasets.
Note
Although this is an example, it should not be considered as a good practice: when doing a data analysis project, you should denormalize the data as soon as possible. Joining three tables to create an analytical dataset is expensive.
We first need to declare our query-based dataset, and to configure the two partitioning dimensions:
A discrete values dimension named “country”
A time dimension on DAY level named “day”
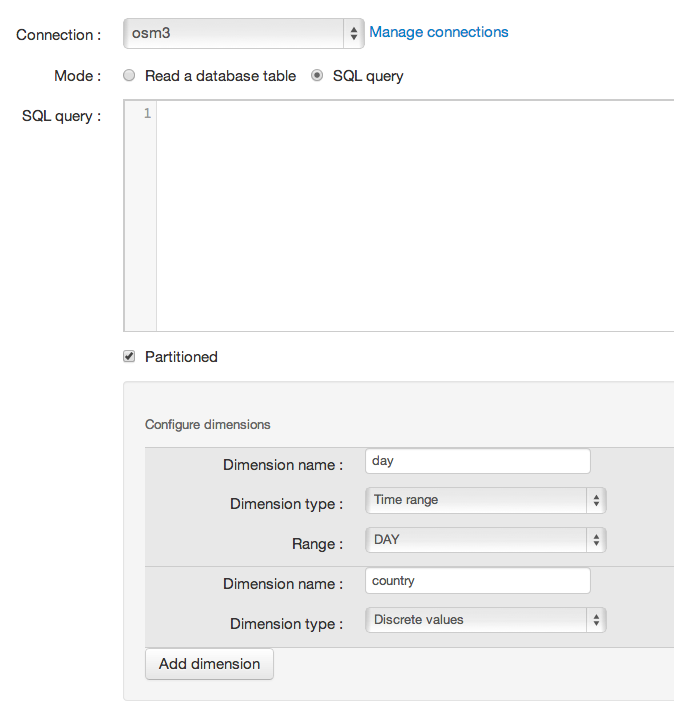
Then, we can create our query. The query must return the records for a single partition. When Dataiku DSS needs to fetch the records of a partition, it will take the SQL query that we have entered, and replace all _${dimensionName}_ patterns in the query by the value of the dimension for this partition.
So our query will be:
SELECT event.type as event_type, user.sex as user_sex, event.timestamp as timestamp, geography.city as geography
FROM event INNER JOIN geography ON geography.id = event.geography_id INNER JOIN user on user.id = event.user_id
WHERE geography.country = '${country}' AND DATE_FORMAT(event.timestamp, 'yyyy-MM-dd') = '${day}'
In the substitution values, a time partition will be given using the DSS partition identifier syntax (see below).
We then need to provide Dataiku DSS with a way to list available partitions. The preferred way is to provide an SQL query able to list partitions. It should return a result set with one column for each partitioning dimension and one row for each partition.
Here, we could achieve this with:
SELECT day, country FROM (
SELECT DATE_FORMAT(event.timestamp, 'yyyy-MM-dd') as day, geography.country FROM event INNER JOIN geography ON geography.id = event.geography_id
) GROUP BY day, country;
The subquery + group is required to perform deduplication of multiple records on the same/day country.
In this example, we can see that listing all partitions is a very costly operation as it needs to perform a full scan of the event table. Due to the reformatting that we have to perform to extract the day, we cannot properly use indices.
On a large event database, that cost might be prohibitively high.
In that case, instead of providing an SQL query to list partitions, we can explicitly list the available partitions by entering something like: 2020-01-01/2020-10-01|france,uk,italy,germany (see Partition identifiers for details).
Note that explicitly listing partitions is generally not desirable for “live” datasets, for which new partitions are created each day.
To finish, we need to explicitly give a partition identifier that Dataiku DSS will use for preview. For example 2020-04-06|france
Writing in partitioned SQL datasets¶
There are two main ways to write in a partitioned SQL table:
Using an SQL recipe or a visual recipe with SQL engine. In that case, see Partitioned SQL recipes.
Using a Sync recipe with optimized engine (S3 to Redshift, Azure to SQLServer, GCS to BigQuery, S3 to Snowflake, WASB to Snowflake, TDCH)
Using any other kind of recipe.
In the last case, the writes are “controlled” by Dataiku DSS (see Recipes for partitioned datasets for more details) and the following is automatically made for you:
Creating the table if it’s not yet created
Checking that the schema of the table is still valid
Dropping pre-existing records corresponding to the partition being written (to ensure idempotence)
Setting the output partition in all records being inserted
You do not need to make sure that the partitioning column appears in the records being inserted. DSS will always fill it with the value of the partition being written. However, it is mandatory to have the partitioning columns appear in the output schema. (This will automatically be done for you if you create the managed dataset by copying the partitioning from another dataset).
SQL datasets and time partitioning¶
When using time-based partitioning on an SQL table, the partitioning columns must NOT be of Date type. Instead, it must be of “string” type and contain values compatible with the partition identifier syntax of Dataiku DSS, that is: 2020-02-28-14 for hour-partitioning 2020-02-28 for day-partitioning 2020-02 for month-partitioning 2020 for year-partitioning
The same is valid for SQL query datasets: the substitution values are given using the partition identifier syntax.
Native partitioning and number of partitions¶
Most database engines do not support an arbitrary number of partitions when using their native partitioning support. For example, Vertica only supports 1024 partitions per table. This might make it impossible to keep, for example, a hour-level partitioning in the database.