
Specifying partition dependencies¶
One of the major features of partitioned datasets is the ability to define partition-level dependencies in recipes. For more information, please refer to the DSS concepts page.
For a given recipe, partition dependencies allow you to compute which partitions of the input datasets are required to compute the requested partition of the output datasets.
Partition dependencies are specified per dimension: for each dimension of each input dataset, a dependency function is used to compute which dimension values are required.
Dependency functions¶
Dependency functions can be “relative” or “absolute”.
“relative” functions return the input values based on the output values
“absolute” functions return the input values without depending on the output values
“Absolute” dependencies are less common and typically used when the output dataset is not partitioned, so “relative” functions are not applicable.
Function |
Type |
Constraints |
Description |
|---|---|---|---|
Equals |
Relative |
Input and output dimensions must be of the same type (and same period for time-based). |
Use the same value |
Time range |
Relative (time) |
Input dimension must be time-based. If there is an output partition, it must also be time-based. There are no constraints on the time levels. |
Yields all time periods in a time range relative to the output. More information about this function is available below. |
Since beginning of week |
Relative (time) |
Input and output dimensions must be time-based.
|
Yields all time periods (days or hours) corresponding to days between the beginning of the week defined by the output and the output date. Stops at the output date. |
Explicit values |
Absolute |
Explicitly lists some values. Note: You can use the partition spec syntax to define ranges. |
|
Latest available |
Absolute |
Lists the partitions of the input dataset available when the recipe is run and selects the “latest” one. For non-time-based dimensions, “latest” is defined as “last by alphabetical ordering”. |
|
All available |
Absolute |
Lists the partitions of the input dataset available when the recipe is run and selects them all. |
Details about the “Time Range” function¶
The “time range” function can be used both as a “relative” or “absolute” function.
Time range generates a list of days or hours between a “FROM” date and a “TO” date.
The “TO” date is expressed relative to:
The output partition date if the output dataset is partitioned
“NOW” if the output dataset is not partitioned
The “FROM” date can be expressed either as:
- A time span relative to
The output partition date if the output dataset is partitioned
“NOW” if the output dataset is not partitioned
An absolute date
Examples¶
From “2020-02-03” to “3 days before output date”
From “7 days before output date” to “1 day before output date”
From “2 months before output date” to “output date”
Available granularities¶
The granularity of the dates is limited by the granularity of the input dimension.
For example, if the input dimension is at “DAY” level, it is possible to specify a dependency as a number of days before, as a number of months before, but not as a number of hours. (It would not be possible to generate a list of partitions with enough precision to actually enforce this constraint)
Interpreting time spans¶
For the “FROM” date and the “TO” date, the time span is inclusive
If a dependency would generate dates after “NOW” (the current date), they are ignored
Examples:
Day-level to Day-level partitioning: “3 days” to “1 days” will include 3 input values
Day-level to Day-level partitioning: “1 month” to “1 days” will go from the beginning of the previous month to the day before (inclusive)
Day-level to Day-level partitioning: “1 month” to “0” will go from the beginning of the previous month to the output day (inclusive)
Day-level to Month-level partitioning: “0 month” to “0” will include the whole output month
Day-level to Not partitioned: “1 month” to “0” will include the previous month and the current month up to the current day
Note about “available” dependencies¶
The “all available” and “latest available” dependency functions are quite special: they can only return partitions that already exist.
Therefore, it is not possible to generate new partitions using these dependencies function.
Consider the following example:
The “logs” and “log2” datasets are partitioned by DAY and we want to compute with SQL a historical report that uses the whole history. A first way that comes to mind is to use a “All available” dependency between “log2” and “report”.
By doing this, however, if new partitions of “logs” become available and you ask to rebuild “report”:
The “all available” dependency will select all partitions of “log2” that already exist
Dependencies engine will check whether they need recomputation
The “new” partitions of “log2” corresponding to the “new” days present in “logs” will not be handled.
To avoid this, you can either:
Build the new partitions of “log2” and then only, build “report”
Use a “time range” dependency. As the output dataset is not partitioned, the time range will be interpreted relative to “NOW”. You setup your dependency to go from “the origin of time for this project” to “0” (ie, to the current day).
Custom partition dependencies¶
For advanced use cases, you can write your own dependency functions in Python.
Example use cases:
One of the input datasets is a referential that gets updated from time to time. The recipe depends on a specific version of the referential, which must be computed
Sometimes, a time-based dataset is not “complete”. For example, a dataset might be produced on the 1st and 15th of each month, and you want to depend on the “proper” one.
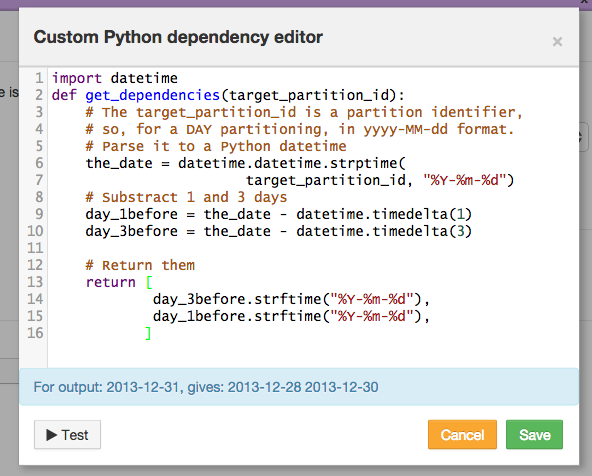
You need to write a single Python function:
def get_dependencies(target_partition_id):
return [partition1, partition2]
The function must return the list of Partition identifiers required to compute target_partition_id of the output dataset.
The following image illustrates a simple example where we always return “the previous day” and “3 days before” as dependency.
Note
Click the “Test” button to test your dependency function on a “randomly” selected target partition