
Evaluating LLMs & GenAI use cases¶
With the adoption of large language models (LLMs), which are able to use natural language as input or output, along with the creation of agents based upon them, the topic of evaluating their performance is both important and not trivial. Standard model evaluation techniques are not well-suited; evaluation of LLMs and agents requires a specific treatment.
This is why Dataiku offers the “Evaluate LLM” and “Evaluate Agent” recipes. These recipes generate various outputs, the most pivotal of which is an evaluation stored in an evaluation store. From this evaluation store, you can then complete your GenAIOps actions with alerting or automated actions.
Note
The “Evaluate LLM” and “Evaluate Agent” recipes are available to customers with the Advanced LLM Mesh add-on.
The specific topic of agent evaluation can be found in Agent Evaluation.
Overview¶
As LLMs and their usage can be quite diverse, the “Evaluate LLM” recipe is meant to be adaptive. Contrary to the standard Evaluate recipe, it does not take a model as a direct input, but a single dataset — the output of your pipeline containing all the required columns: input, output, context, ground truth, etc…
With this logic, the recipe can be used directly beyond a Prompt recipe to evaluate an LLM, or a RAG, but it can also be used at the end of a more complex pipeline that uses several techniques, models, and recipes.
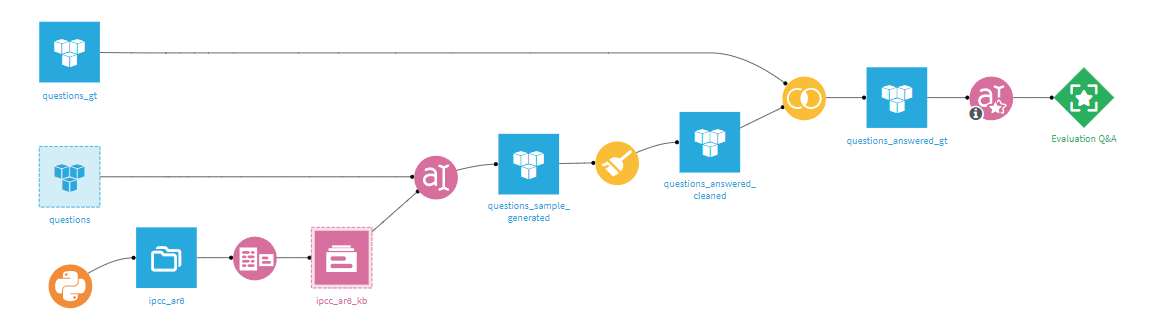
When run, the recipe will compute a set of metrics based on the content of the input dataset and create a single LLM evaluation.
Note
Our LLM evaluation tutorial provides a step-by-step explanation of how to create your first LLM evaluation Flow. Do not hesitate to do it as a first experience.
There are some pre-requisites for a working recipe. Those requirements are to be done once, but may require the assistance of your instance administrator.
You need to have a code environment with the required preset installed (using Python 3.9+). Look for the preset called “Agent and LLM Evaluation”.
For most metrics, you will need an LLM to compute embeddings and an LLM for generic completion queries. These LLMs are to be selected from Dataiku’s LLM Mesh.
Recipe configuration¶
You can create an “Evaluate LLM” recipe from any dataset.
If this is your first experience with the recipe, take a dataset out of a Prompt recipe and use the predefined setup:
In the “Input dataset” section, set the Input Dataset Format to “Prompt Recipe” and the task to the relevant type (for example “Question answering”).
Ensure you have a proper code environment and LLMs for embedding and completion.
Finally, click on the “SELECT COMPUTABLE METRICS” button. All relevant and computable metrics will be selected for you.
With that, you should be able to run your first LLM evaluation. For the sake of understanding, let’s dive a bit more into each section to explain it.
Input dataset¶
The Input Dataset Format allows the use of presets for some common tasks in DSS:
Prompt Recipe: The Input Dataset is the output dataset of the Prompt recipe.
Dataiku Answers: The Input Dataset is the conversation history dataset of the solution.
The “Task” selection allows Dataiku to better guide you in setting up the recipe. If you are not satisfied with any option, you can always use the generic “Other LLM Evaluation Task”. In addition to helpers on the expected columns, the choice of task will also influence the computable metrics.
Metrics¶
The “Metrics” section is where you will define the core of the recipe. If you have selected a Task, Dataiku will highlight recommended metrics, but you can always remove metrics you are not interested in.
Below this list, you will need to enter the LLM to use to compute embeddings and the LLM for LLM-as-a-judge metrics. Those fields are not mandatory, as some metrics do not require any LLM, such as BLEU or ROUGE, but most metrics will need those models.
BLEU and ROUGE are metrics based on exact matching of words, specialised in, respectively, translation and summarization.
BERTScore is based on matching of embeddings, but uses an internal embedding model, fetched from HuggingFace (list of possible models). This is not an LLM-as-a-judge metric : its results are deterministic.
The other metrics (Answer correctness, Answer relevancy, Answer similarity, Context precision, Context recall, Faithfulness) are LLM-as-a-judge metrics. If you want more in-depth understanding, you can read the RAGAS documentation. Note that LLM-as-a-judge metrics are computed row-by-row, and the recipe will compute the average for all rows as its final value.
Note
Your instance administrator can setup a default code environment and default LLMs for all “Evaluate LLM” recipes. Look in the section Administration > Settings > LLM Mesh > Evaluation recipes.
Custom Metrics¶
As LLM evaluation is a quickly evolving topic, the recipe allows you to write your own metric in Python. This is done using a standard “evaluate” function and should return at least one float representing the metric.
Additionally, you can return an array of floats, each entry being the metric value for a single row. This will be used in the row-by-row analysis.
Code samples are available, which can make your first experience with custom metrics easier, or allow you to define your own samples to be reused later.
LLM Evaluations¶
Each run of the “Evaluate LLM” recipe will create one LLM evaluation. This LLM evaluation will be visible in the output evaluation store.
In the main view of an LLM evaluation, you see plotted metric graphics at the top and the list of LLM evaluations at the bottom, including metadata, labels, and metrics in a table.
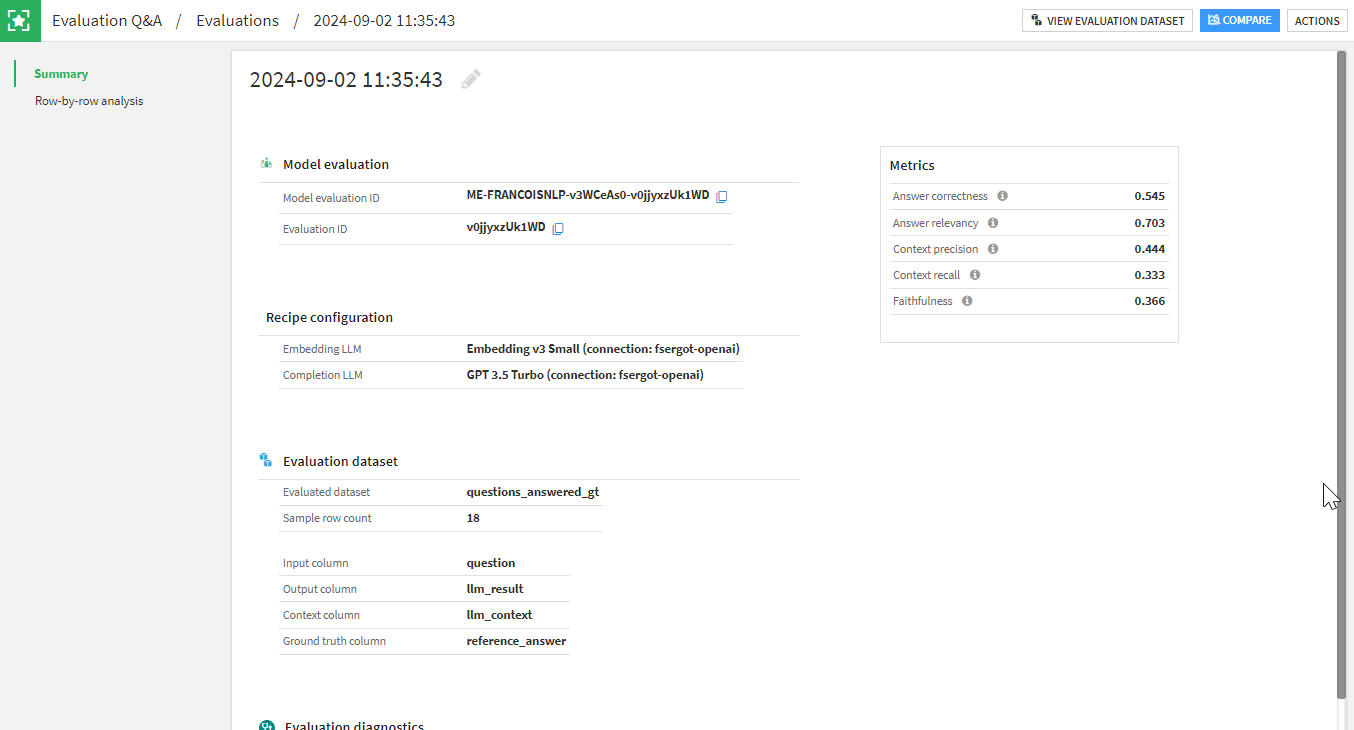
When you open an LLM evaluation, the first section contains: run info, the recipe configuration at the time of the run, and all metrics. You also see the labels that were added during the execution of the recipe. You can add, update or delete labels if you want.
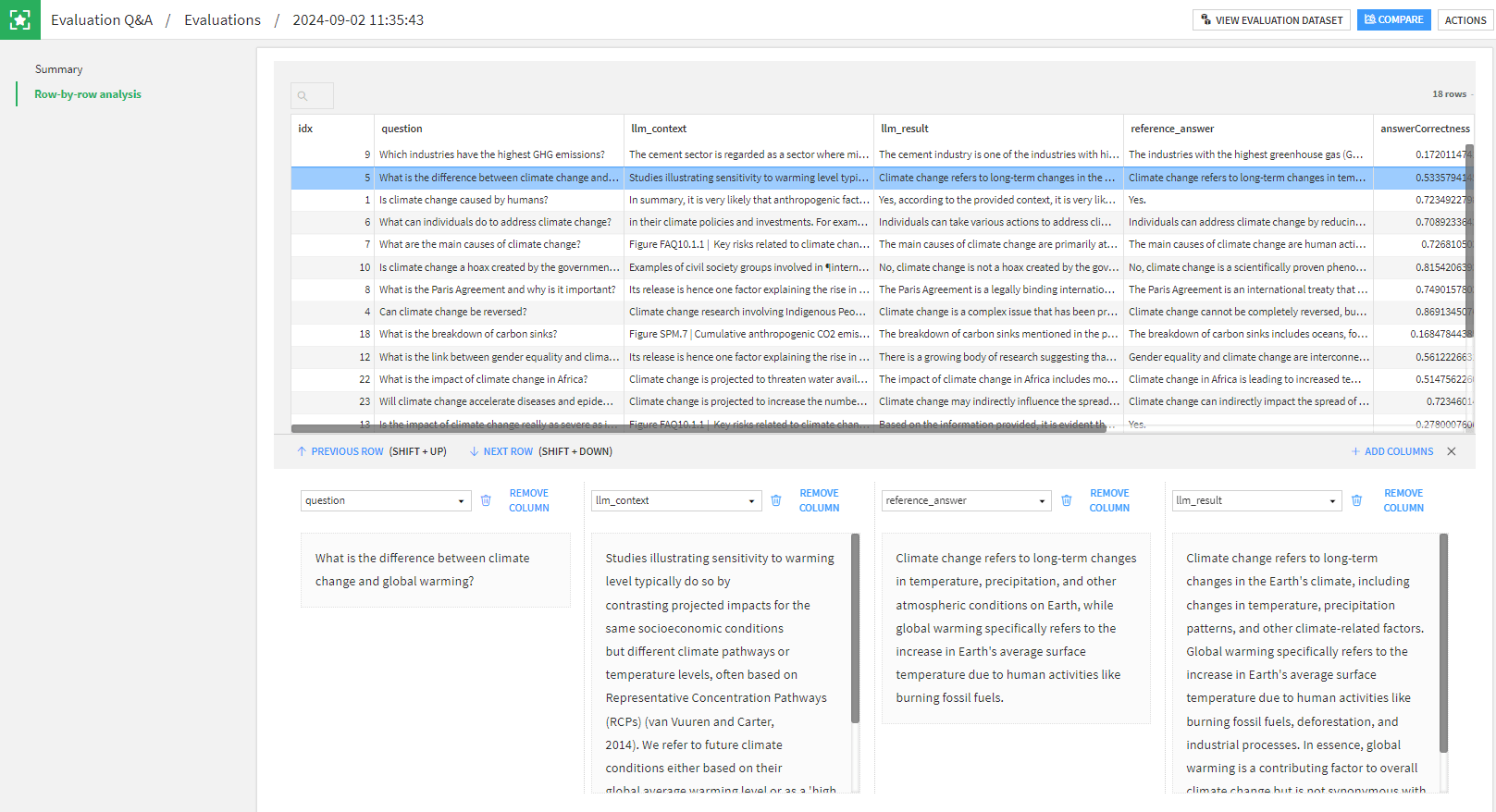
The second section of an LLM evaluation is a row-by-row detail. This aims at helping you understand specific values of metrics, by giving you the context (row values) that precluded the value of each metric. As an example, if you have a particularly low faithfulness score, you can look at the context and the answer and assess it with your own judgement.
If you have defined custom metrics, they will be shown in the LLM evaluation summary along other metrics. If your custom metric returned the array with detailed values, you will also see it in the row-by-row analysis.
Comparisons¶
This row-by-row view is very practical to analyze specific cases in a run. However, when building a complex GenAI pipeline, you will probably experiment with different LLM, different prompts, different pre- or post- processing. In such a case, the goal is not to analyze, but to compare runs using potentially very different pipelines.
Comparing runs is using model comparisons. As a specific addition to the standard model comparison, the LLM Comparison has a section allowing you to perform side-by-side view for each row.
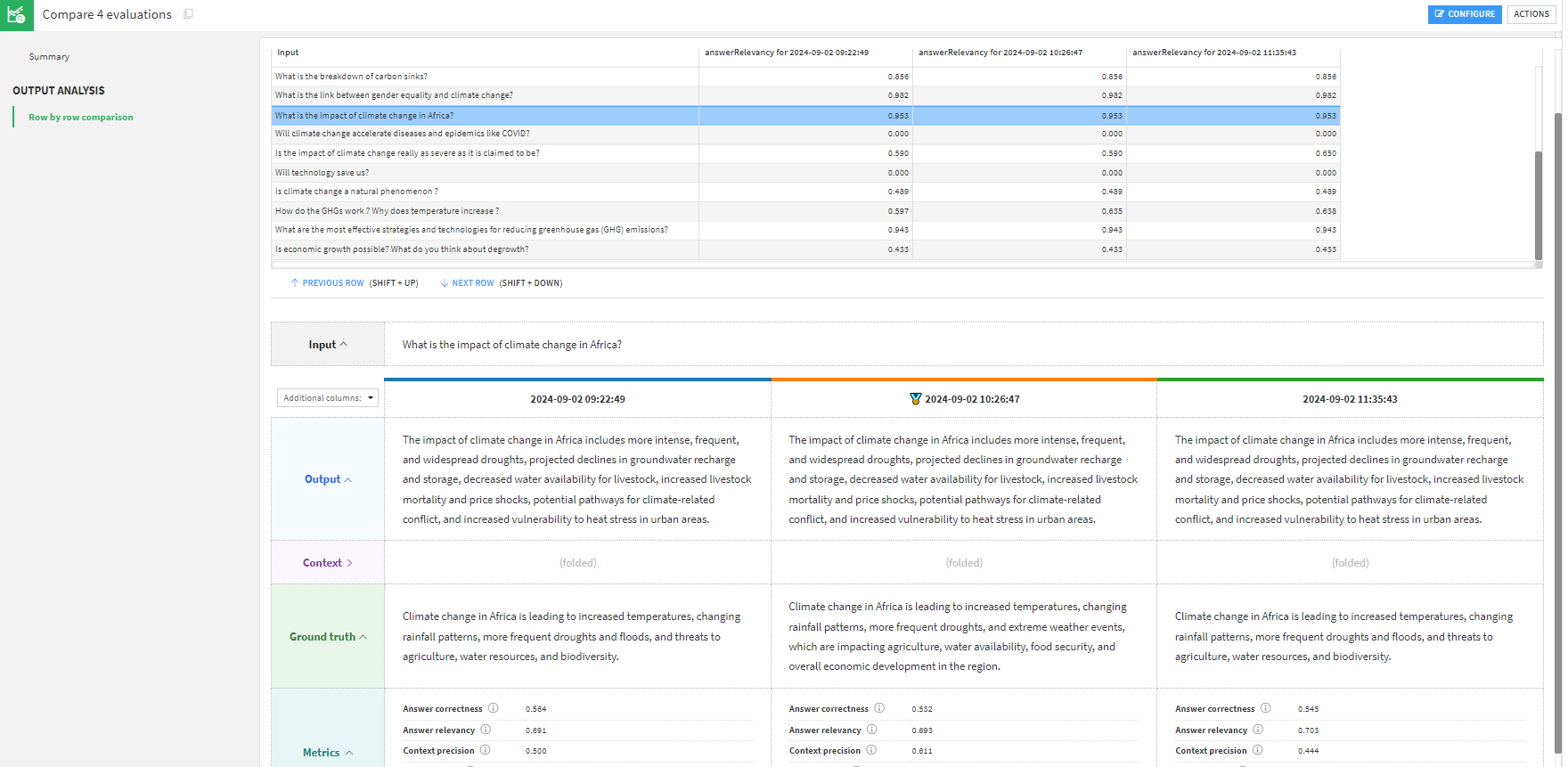
In this screen, you can select a row, and you will see outputs of each run. This allows you, for example, to spot a line where the answer relevancy is vastly different between two runs and analyze it in depth to make an informed decision about which version of your pipeline is best.