
Rebuilding Datasets¶
When you make changes to recipes within a Flow, or there is new data arriving in your source datasets, you will want to rebuild datasets to reflect these changes. There are multiple options for propagating these changes. This page illustrates the case of Datasets, but is also valid for Models and Folders. Datasets can also be built by running recipes, when running a recipe you also have the options listed in this document.
See also
For more information, see also the following articles in the Knowledge Base:
Build modes¶
There are 3 main modes for building a dataset. Right-click on the dataset and select Build, then select one of the following options.
Build only this (Non recursive)¶
Builds the selected dataset using its parent recipe. This option requires the least computation, but only includes changes to datasets that are inputs of the parent recipe, and does not take into account any changes further upstream.
Build upstream (recursive)¶
Builds the selected dataset and upstream datasets. There are two types of upstream builds
Build only modified: Checks each dataset and recipe upstream of the selected dataset. Dataiku DSS then rebuilds all datasets from the first outdated dataset down to the selected one. This is the recommended default. More details in the note below.
Build all upstream: Rebuilds all dependencies (unless specified by Rebuild behavior ) of the selected datasets going back to the start of the flow. This is the most computationally-intense operation. But, for example, it can be used for scheduled builds outside working hours that ensure the flow is completely up to date.
In both cases, you can also use the Stop at zone boundary option. This means that upstream dependencies will only checked if they are located in the same flow zone as the selected dataset.
Note
In Build only modified mode, or where an options says Build required dependencies, DSS checks all datasets and recipes upstream, and datasets are considered outdated and will be rebuilt if any of the below are true:
A recipe upstream has been modified. If this is the case, its output dataset is considered out-of-date.
A recipe upstream has had one or more inputs modified. If this is the case, its output dataset is considered out-of-date
The settings of a dataset upstream have changed.
- For external datasets (datasets not managed by DSS):
File based datasets: Check the marker file if there is one; otherwise, check if the content of the dataset has changed. DSS uses filesystem metadata to identify if there has been a change in the file list (e.g. files added/removed) or any files themselves (e.g. size, last modification date).
Snowflake and BigQuery datasets: Optionally, DSS can check the timestamp of the last modification using the metadata of the underlying table. Note that this option is only available for unpartitioned datasets. Warning: Changing this setting will make DSS treat all external Snowflake or BigQuery datasets as modified, so it will rebuild them and their downstream dependencies on the next recursive build.
For other SQL datasets: DSS considers it up-to-date by default, as it is difficult to know if there is a change in an input SQL dataset.
Known limitation: Build only modified can’t take into account variable changes in visual recipe; you have to force a rebuild.
Build downstream (recursive)¶
Builds downstream datasets. In advanced settings :
Build all downstream: This runs recipes from the selected dataset until the end of the Flow is reached (unless specified by Rebuild behavior ). The selected dataset itself is not built.
Find outputs and build recursively: Dataiku DSS will find all final datasets downstream from selected dataset and build any upstream dependencies. In this case, you can choose to either build required dependencies or force-build those upstream datasets.
Rebuild behavior¶
Datasets, folders and models can be configured on the Advanced settings in order to control the Rebuild behavior.
Preventing a Dataset from being built¶
You might want to prevent some datasets from being rebuilt, for instance, if rebuilding them is particularly expensive or if their unavailability must be restricted to certain hours. In a dataset’s Settings > Advanced tab, you can configure its Rebuild behavior:
Normal: the dataset can be rebuilt, including recursively in the cases described above.
Explicit: the dataset can be rebuilt, but only if it is specifically the target of the build.
Write-protected: the dataset cannot be rebuilt, even explicitly, making it effectively read-only from the Flow’s perspective.
Note
When an explicit or write-protected dataset is included in a recursive build, it will not be rebuilt, and the exact behavior depends on the option chosen.
Given a flow such as the following, with B set as Explicit or Write-protected.
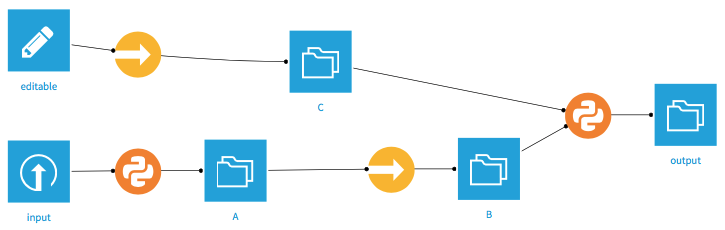
Build upstream (from output): Will only rebuild C (and output). B will not be rebuilt, nor will its upstream datasets.
- Build downstream (from input)
Build all downstream: This will build A, skip the sync recipe and NOT build B, and then build output
Find outputs and build recursively: Will only rebuild C (and output). B will not be rebuilt, nor will its upstream datasets.
Explicit Datasets can be rebuilt if they are the direct target of a build when using Build only this or Build upstream modes.
Note
You can still write to Write-protected datasets from a Notebook.
Behavior is the same when building from a Scenario or via an API call.
Allow build to continue when a Data Quality rule fails¶
By default, when building a dataset, any auto-computed Data Quality rules with an error status will prevent recursive build to continue. However you might want to allow recursive build to carry on for example when the downstream recipe is the Extract failed rows recipe. If so, check the option in the dataset’s Settings > Advanced > Allow build to continue when rule fails.
Preventing a Model from being retrained¶
Similarly, you might want to prevent some models from being retrained, for instance, if retraining them is particularly expensive or if you want to have more control on the model.
In a model’s Settings > Recursive build behavior, you can configure its Retrain behavior. It works the same way as Dataset with minor differences :
Models are by default set as Explicit
Models cannot be set as Write-protected
Propagate schema across Flow from here¶
This option propagates changes to the columns of a dataset to all downstream datasets. The schema can have changed either because the columns in the source data have changed or because you have made changes to the recipe that creates the dataset. To do this, right-click a recipe or dataset and select Propagate schema across Flow from here.
This opens the Schema Propagation tool. Click Start to begin manual schema propagation, then for each recipe that needs an update:
Open it, preferably in a new tab
Force a save of the recipe: hit Ctrl+s, (or modify anything, click Save, revert the change, save again). For most recipe types, saving it triggers a schema check, which will detect the need for an update and offer to fix the output schema. DSS will not silently update the output schema, as it could break other recipes relying on this schema. But most of the time, the desired action is to accept and click Update Schema.
You probably need to run the recipe again
Some recipe types cannot be automatically checked; for example, Python recipes.
Some options in the tool allow you to automate schema propagation:
Perform all actions automatically: when selected, schema propagation will automatically rebuild datasets and recipes to achieve full schema propagation with minimal user intervention.
Perform all actions automatically and build all output datasets afterwards: As the previous option, plus a standard recursive Build All operation invoked at the end of the schema propagation.
Note
If your schema changes would break the settings of a downstream recipe, then you will need to manually fix the recipe and restart the automatic schema propagation. For example, if you manually selected columns to keep in a Join recipe (rather than automatically keeping all columns), and then delete one of those selected columns in an upstream Prepare recipe, then automatic schema propagation will fail at the Join recipe.
Advanced Options¶
You have Advanced options related to schema updates :
Rebuild input datasets of recipes whose output schema may depend on input data (prepare, pivot):
If this option is selected, then the schema propagation will automatically rebuild datasets as necessary to ensure that the output schemas from the recipe can be correctly calculated. This is particularly important for Pivot recipes and Prepare recipes with pivot steps. If you have no such recipes it may faster to deselect this.
Rebuild output datasets of recipes whose output schema is computed at runtime:
Selecting this will ensure the rebuild of:
all code recipes
Pivot recipes which are set to “recompute schema on each run” in the Output step
Schemas for Prepare recipes should update automatically even if this is not selected.