
Enriching prediction queries¶
The basic use case for the API node is fairly simple: send the features of a record, receive the prediction for this record.
However, there are many situations in which all features of an input record are not easily known by the API user. DSS API node includes a data enrichment feature that makes these scenarios easy to handle.
Use case¶
For example, consider the following case: we are creating a fraud detection engine for an e-commerce website. The model is trained using historical data from the users, orders, and products database, and labeled data from the fraud department.
The final dataset used to train the model contains:
Information about the “current” order
Information about the “current” payment method
Historical aggregated data about the customer: total number of orders, total value, number of payment modes, …
Aggregated data about the product in the order: category, number of previously fraudulent order for this product, …
Therefore, to score a new record, we need all this information. However, when the backend of the website (i.e. the caller of the API) wants to obtain the prediction, it only has access to the information about the current order and payment, not the historical aggregates of customer and product.
However:
the website backend has the
customer_idand theproduct_idreadily available.the historical data aggregates are available in DSS.
By using the data enrichment feature of DSS API node, you can declare in the configuration of your endpoint an enrichment of the records to predict by the customer_data and product_data tables.
The API caller sends the
customer_idand theproduct_idvalues as features of the recordDSS API node looks these up in the
customer_dataandproduct_datatablesDSS API node replaces the customer_id and product_id by the data from the data tables.
The prediction can then happen normally
Configuration¶
Note
This information is also valid for the dataset lookup endpoint
Configuring data enrichments is made in the Endpoint > “Features mapping” section in DSS. Multiple enrichments are possible.
You must configure:
Which dataset is used for enrichment
How the dataset will be deployed for lookups (See the “Deployment options” section below)
How the lookup keys in the features of the records will be mapped to column lookups in the dataset
Which columns of the dataset will be retrieved and how they will be mapped to features in the record.
Lookup mapping¶
Lookup keys definition is configured by selecting:
one or multiple column(s) forming a lookup key in the enrichment dataset
for each column of the key, their corresponding name in the query (in the case they must be different).
Retrieved columns¶
Retrieval of columns as features in the record is configured by selecting:
the appropriate columns from the enrichment dataset
for each retrieved column, the name of the corresponding feature as expected by the model (in the case they are different).
Error handling¶
You can configure how API node should react in various abnormal situations:
Unspecified key: the input record does not contain the lookup key(s)
No match: no row in the dataset matches the lookup key(s)
Several matches: multiple rows in the dataset match the lookup key(s)
Deployment options¶
There are two possible deployment options for data enrichments.
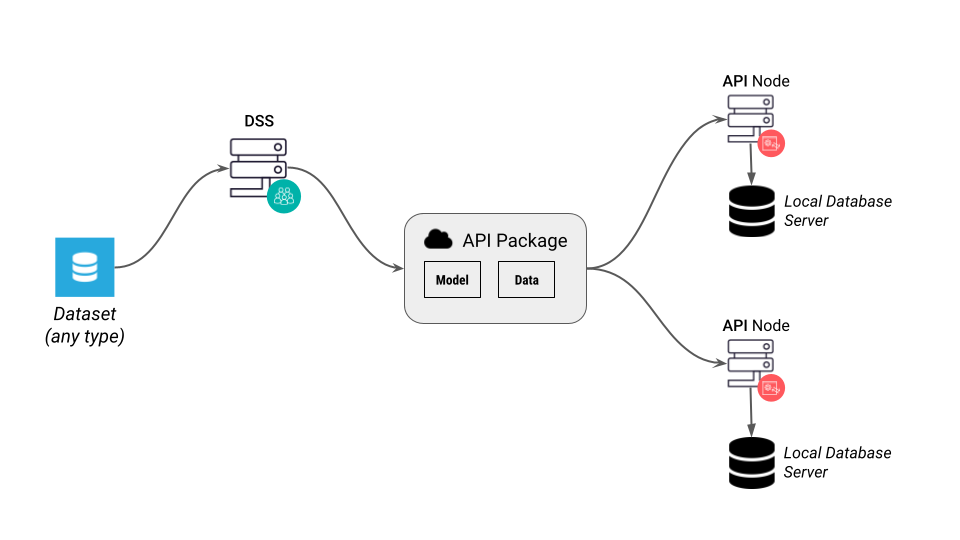
Bundled data¶
The “bundled data” mode is the simplest deployment mode and should generally be preferred when the lookup tables are fairly small (up to a few million lines).
In this mode:
each DSS API node instance must have a private connection to a supported SQL database, see API Node Configuration below.
The contents of the dataset is copied in the package file when you create a new package
When you import a package to a DSS API node instance, the contents of the data from the package is copied to the private SQL database
The API node automatically uses the SQL database
The private SQL database is not part of the API node instance. You need to install a compatible database. Any SQL database supported by DSS can be used. However, we recommend to use databases that are well suited for random lookups i.e. not an analytics-oriented database.
Note that the database does not need to reside on the same host as the API node instance. It is, however, recommended to have both API node server and database server on the same host. This way, each physical server is fully independent, which reduces the failure mode and makes handling a down server easier.
Referenced data¶
In this mode, the data for the lookup tables itself is not managed by the API node. Each API node instance must have in its settings the details for a DSS connection where the lookup data must be available.
This mode is only available for SQL datasets.
When you export a package from DSS, the package does not contain the data. It only contains a reference to the original dataset, ie a connection name and a table name.
Each API node instance has configuration that tells it how to connect to this connection name, see API Node Configuration below.
In almost all cases, the DB server queried by API node instances must not be the one used for preparing the Flow in DSS. You will therefore need to set up some kind of replication from the “original” data in a connection known by DSS to another “prod” database known by the API nodes.
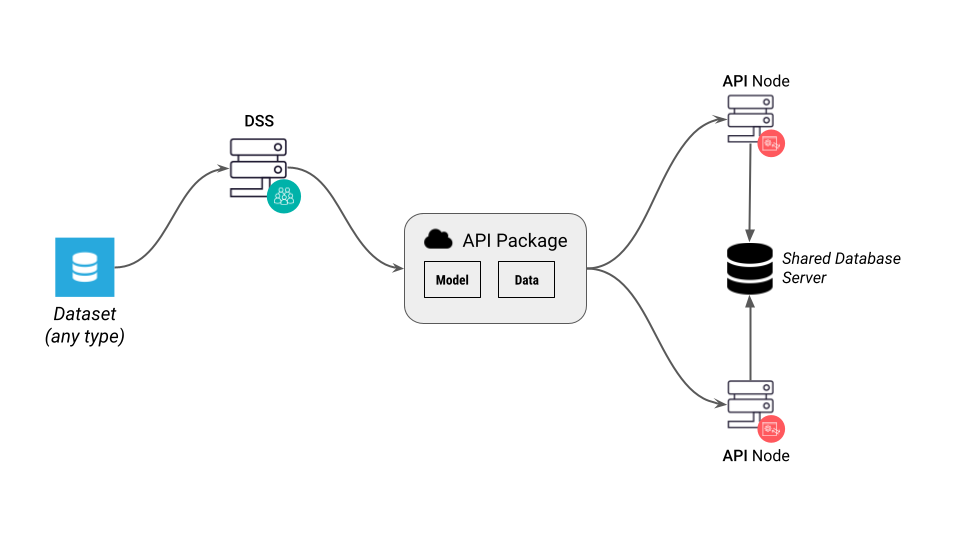
Each API node can have its own definition of “where the database” is, by having different connection parameters. This allows you to actually have several database servers, and each API node querying one of them.
Note
If several (or all) API node servers have the same reference to the production database, it is important that this production database be itself highly available.
API Node Configuration¶
Note
This does not apply to Kubernetes deployments using API Deployer
Bundled data requires the API node to have a private connection to an SQL database. In the API node’s DATA_DIR/config/server.json, add a top-level bundledConnection object:
{
"bundledConnection": {
"type": "PostgreSQL",
"params": {
"host": "my-db-host",
"db": "my-db",
"user": "my-user",
"password": "my-password"
}
},
"..."
}
When testing bundled data in your services with the “Run test queries” button or the “Deploy to dev server” menu, the DSS administrator must first set
a DSS SQL connection as the development server’s bundledConnection in the Administration > Settings > Deployer under “API Designer: Testing” section. Afterwards, make sure to Save the changes and restart the “Test server” for these changes to take effect on your local Dev server.
For referenced data, the API node must have remapped connections whose names match those of the connections with which the package was created.
Add these remapped connections in a top-level remappedConnections in the API node’s DATA_DIR/config/server.json:
{
"remappedConnections": {
"MY-SAMPLE-CONNECTION": {
"type": "PostgreSQL",
"params": {
"host": "my-db-host",
"db": "my-db",
"user": "my-user",
"password": "my-password"
}
},
"MY-OTHER-CONNECTION": { "..." }
},
"..."
}