
Schema for data preparation¶
Data preparation can be accessed in two parts in DSS:
In the Lab, through the Visual analysis. This is used to iterate between preparation, visualization and machine learning.
In a Prepare recipe in the Flow, used to create a new dataset
In Data Preparation, meanings are used to automatically suggest relevant transformations (either when clicking on a column header or on a cell).
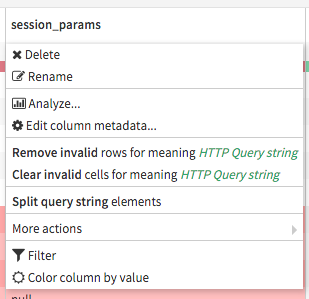
In this example, the column has a meaning of “HTTP Query string” and has invalid values, so DSS suggests both removal of invalid values and query-string-specific operations.
Schema in visual analysis¶
A visual analysis is a pure “Lab” object, which does not have persistence of output data. As such, columns in analysis don’t have a notion of storage types (since they are not stored).
In analysis, only meanings are shown.
When you create an analysis from a dataset, the forced meanings and column descriptions are carried over from the dataset.
Schema in prepare recipe¶
When you create a data preparation recipe, DSS automatically sets the schema of the output dataset. At creation time, the forced meanings and column descriptions are carried over from the input to the output dataset.
The schema of the output dataset may or may not be inferred, depending on the data type mode selected in Administration > Settings > Other > Misc > Prepare recipe type inference. There are three modes:
Lock strongly typed inputs: Infer data types for loosely-typed input dataset formats (e.g. CSV) and lock for strongly-typed ones (e.g. SQL, Parquet). For a SQL dataset for example, any column of the output dataset present in the input dataset will retain consistent data types. This is the default behavior for DSS 12 onwards.
Always infer: Infer data types for all input dataset formats. This was the default behavior prior to DSS 12.
Lock all inputs: Not recommended. Preemptively lock the data types of the input columns and only infer for new columns.
With the first and second modes, the schema of the output dataset for a loosely-typed input (e.g. CSV) is inferred by computing the “best” storage type matching the data in the sample. If no “best” storage type is found, DSS defaults to a “string” column.
Type inference allows the prepare recipe to benefit from all of its functionality. For example, type inference ensures that numeric columns from a CSV will actually be treated as numbers rather than strings, so that 5+5 will return 10 rather than 55.
Since storage types use strict interpretation of what data is valid, you may need to parse or format the data before being able to use it with a precise storage type. For example, the string “1 245,21” has meaning “Decimal (comma)”, but is not valid for the “double” storage type, which only accepts “raw” decimals (i.e. “1245.21”). You need to use a “Numerical format converter” processor to convert to proper raw decimals.
In the UI of the Prepare recipe, both the meaning of the column and the storage type in the output dataset are displayed. When you change the storage type there, it changes what will be stored in the output dataset. Types that appear in white are “possible”, while those appearing in red will generate errors or warnings.
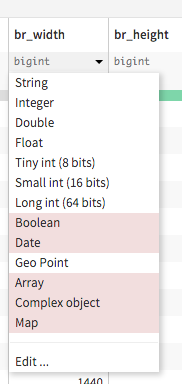
By default, DSS discards invalid data when storing in the output dataset.
Note that the modification is only applied when you Save the recipe.