
Launching a scenario¶
Scenarios can be started manually, or using the DSS Public API.
Triggers are used to automatically start a scenario, based on several conditions.
Each trigger can be enabled or disabled. In addition, the scenario must be marked as “active” for triggers to be evaluated.
Types of triggers¶
In order to cover most usage cases, several types of triggers exist.
Note
If a scenarios contains multiple active triggers, the trigger conditions are evaluated independently. This means that the scenario will be triggered when any trigger condition is true.
Time-based triggers¶
These triggers launch scenarios at regular intervals. The periodicity can be monthly, weekly, daily or hourly. Within each period, a given time point is chosen when the scenario is to run (minute of hour, hour of day, …)
Trigger on dataset change¶
These triggers start a scenario whenever a dataset is changed, data-wise or settings-wise. Detection of changes to the data depends on the type of dataset. For filesystem-like datasets (Uploaded, Filesystem, HDFS), a change means a discrepancy in the file names, lengths or last modification time.
For SQL-like datasets however, changes to the data are not detected and a SQL trigger should be used.
Optionally, for filesystem-like datasets, it is possible to specify a file name as a “marker” file whose changing is understood as “the data has changed”. When a marker file is specified, changing the other files of the data doesn’t activate the dataset modification trigger. This makes it possible to prevent the trigger from activating while the dataset files are being modified, and protects against situation where refreshing of a dataset can hang.
Trigger on SQL query change¶
When the data is stored in a SQL database, one can usually check changes with a query, for example selecting the maximum of some date. A SQL trigger runs a query and activates when the output of the query changes (w.r.t. the last execution of the query).
Trigger after scenario¶
These triggers start a scenario after the end of another scenario, optionally with a condition on the followed scenario’s outcome (only if successful, only if failed,…).
Python triggers¶
Where a fully flexible approach is required, a Python trigger can be set up. This type of trigger executes a Python script, and the script can decide to activate the trigger. This makes it possible to query external APIs and do all sorts of checks.
Trigger parameters¶
Triggers can pass parameters to the steps and scripts executed in a scenario run. All triggers pass at least their name and type, but some triggers pass additional data:
SQL triggers pass the output of the query
Python triggers may pass any data
Manual triggers¶
When you manually run a scenario (either through the DSS UI, or through the public API), you are actually using a specific “manual” trigger. The manual trigger may send parameters, which will be received like other trigger parameters.
To pass parameters through the UI, use the “Run with custom parameters” button in the Actions menu.
See the public API doc for information on how to trigger a scenario through the API.
Evaluation¶
Each trigger has an evaluation interval. DSS will perform the verification (Files timestamps, SQL query, Python code) at each interval.
Note
Time-based triggers do not have an evaluation interval.
Examples¶
Launch a scenario every day at 10:00PM¶
add a Time-based trigger
set its frequency to
Dailyset the field every day at to
22:00
Launch a scenario whenever a HDFS dataset changes¶
add a Trigger on dataset change
select a dataset
set the check periodicity
Launch a scenario whenever a SQL dataset changes¶
The dataset change triggers do not read the data, only the dataset’s settings, and in the case of datasets based on files, the files’ size and last modified date. These triggers will thus not see changes on a SQL dataset, for example on a SQL table not managed by DSS. For these cases, a SQL query change trigger is needed.
add a Trigger on SQL query change
write a query that will return a value which changes when the data changes. For example, a row count, or the maximum of some column in the dataset’s table.
set the check periodicity
Trigger handling¶
Triggers are evaluated independently from scenario runs. When a trigger evaluates to true, its scenario is promoted for execution. Promoting for execution doesn’t imply that the scenario starts right away. Whether the scenario starts immediately or not depends on the settings of the scenario and of the trigger.
Simple case¶
A simple scenario with a single temporal trigger, like:
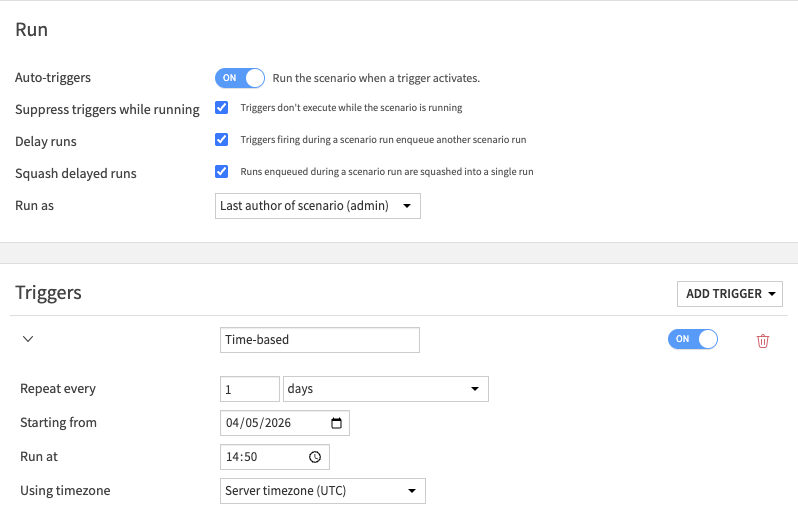
In such a case, the trigger evaluates to true once a day, and the scenario runs right after:
|
| <--- trigger evaluates to true
| <--- scenario run starts
|
| <--- scenario run ends
|
...
|
| <--- trigger evaluates to true
| <--- scenario run starts
|
| <--- scenario run ends
Suppressing triggers during runs¶
By default, when activating auto-triggers, the option Suppress triggers while running is enabled. This means that triggers are only evaluated (to true or false) when their scenario is not currently running. For example in a scenario with two temporal triggers, and a scenario that could be running for more than the time between the first and second trigger:
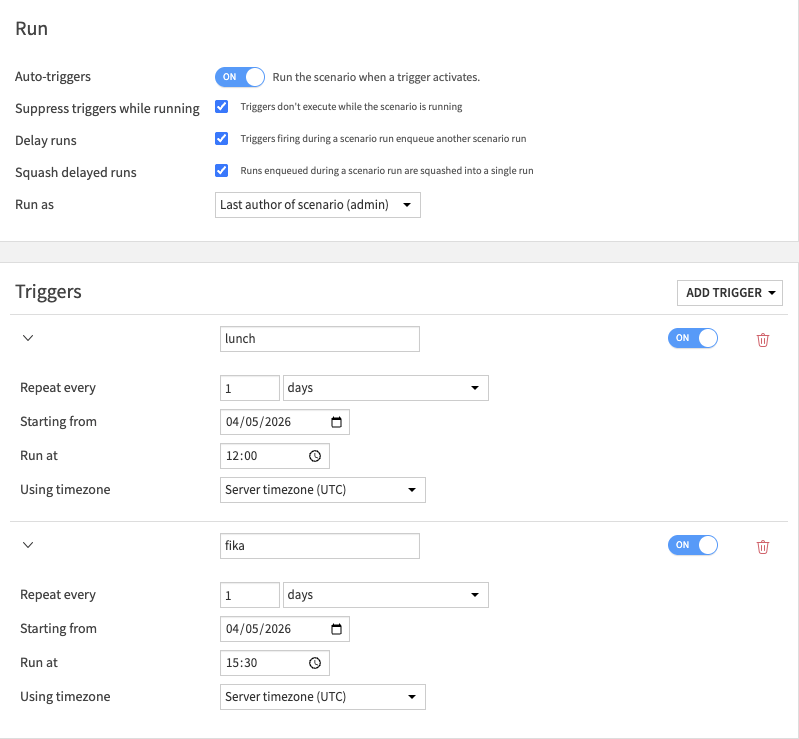
Depending on the duration of the runs, the second trigger may simply not get evaluated
|
| <--- lunch evaluates to true
| <--- scenario run starts
| ... runs for 2 hours
| <--- scenario run ends
|
|
| <--- fika evaluates to true
| <--- scenario run starts
| ... runs
| <--- scenario run ends
|
...
| <--- lunch evaluates to true
| <--- scenario run starts
| ... runs for 3 hours 30 mins
| - - fika is not evaluated, just schedules itself on the next day
| ... runs some more
| <--- scenario run ends
|
If triggers are not suppressed during scenario runs, they are evaluated, but if the scenario run is still underway when the trigger finishes evaluating, then the trigger evaluation is ignored. Not suppressing triggers during scenario runs thus only makes sense if the scenario runs are short and the trigger evaluations long.
Delaying runs¶
The default settings suppress triggers during scenario runs, but sometimes each event tracked by a trigger should result in a scenario run. In that case, Suppress triggers while running should be disabled, Delay runs enabled, and Squash delayed runs disabled. If you have several events followed by triggers, and a scenario that can take some time to run, like:
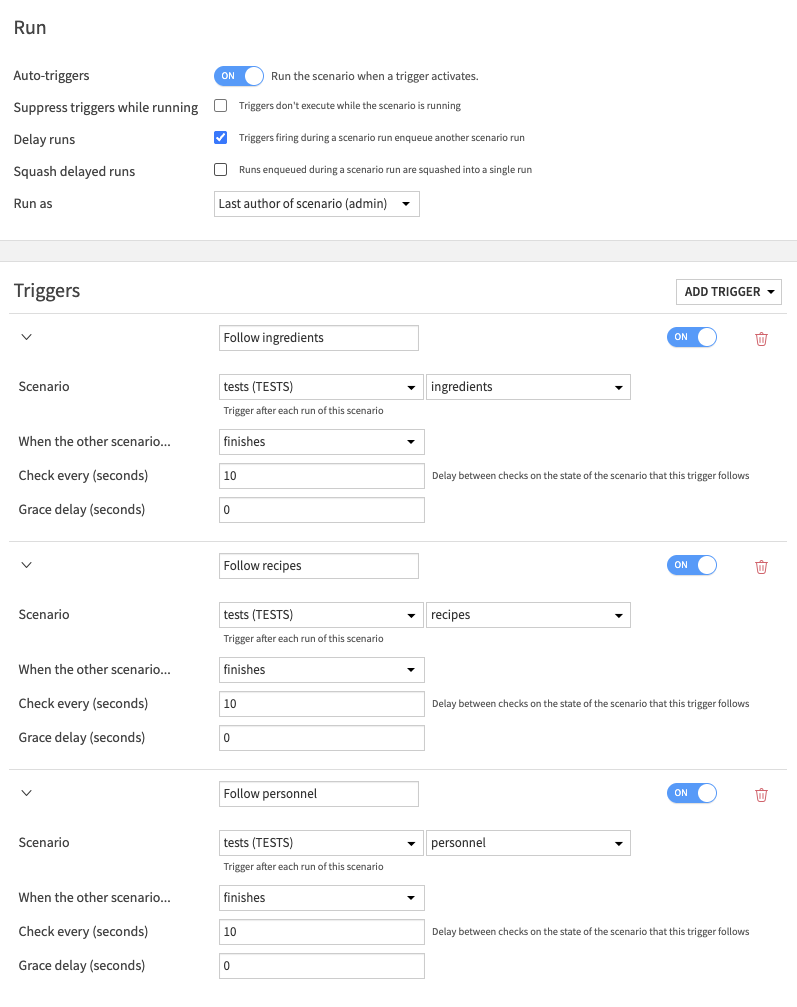
Then you get one run per trigger.
|
| <--- ingredients evaluates to true
| <--- scenario run for ingredient starts
| ...
| <--- personnel evaluates to true
| ...
| <--- scenario run for ingredient ends
| <--- scenario run for personnel starts (right after)
| ...
| <--- scenario run for personnel ends
|
|
| <--- ingredients evaluates to true
| <--- scenario run for ingredient starts
| ...
| <--- personnel evaluates to true
| ...
| <--- recipes evaluates to true
| ...
| <--- scenario run for ingredient ends
| <--- scenario run for personnel starts (right after)
| ...
| <--- scenario run for personnel ends
| <--- scenario run for recipes starts (right after)
| ...
| <--- scenario run for recipes ends
|
Since scenarios don’t have parallel runs, this approach only works if the scenario’s runs can catch up to the triggers throughput. If there are 4 triggers per hour and the scenario runs last 30 minutes (so max 2 runs per hour), then the delayed runs will accumulate over time. For this reason, it’s safer to leave Squash delayed runs enabled, so that there is at most one delayed run. Then you’d get:
| <--- ingredients evaluates to true
| <--- scenario run for ingredient starts
| ...
| <--- personnel evaluates to true
| ...
| <--- recipes evaluates to true
| ...
| <--- scenario run for ingredient ends
| <--- scenario run for recipes starts (the run for personnel is cancelled)
| ...
| <--- scenario run for recipes ends
|
Note
Some types of triggers are not covered by run delaying: time-based triggers and manual triggers (i.e. clicking on Run in the UI). The hidden triggers created by scenario steps of type Run another scenario also can’t be delayed.
Grace delays¶
Triggers observing the state of some external resource will typically evaluate to true whenever a change in said external resource is noticed. When the external resource changes, in some cases it will keep changing for a while. For example if the external resource is a folder in which files are periodically dropped, the changes are files being added, and data being appended to the files. Depending on the number of files and their size, the folder can keep changing for several minutes. To make the trigger wait for the state of the external resource to settle, activate a Grace delay, ideally with Re-check enabled. Then for
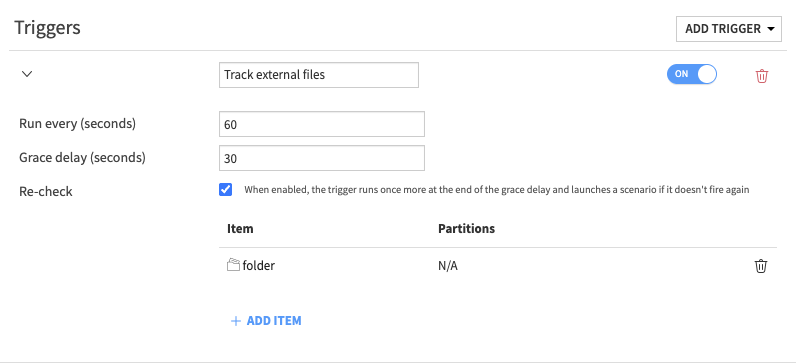
You’ll get something like
|
| - - uploading of file(s) starts
| <--- A: trigger evaluates to true, doesn't start a run
| ... 30s ... files still being modified
| <--- B: trigger evaluates, still true, doesn't start a run
| ... 30s ... files stop changing after 10s
| <--- C: trigger evaluates, still true, doesn't start a run
| ... 30s ... files not changing
| <--- trigger evaluates, now false (same observed value as in C), starts a run
| <--- scenario run starts
|
| <--- scenario run ends
|
Note
The effective trigger for the scenario run is the last one that evaluated to true (in the above example, it’s C)
In cases where a bound on the amount of time needed for the observed resource to stop changing is known, the Re-check can be disabled. For example, if in the above case we know it shouldn’t take more than 90 seconds to upload the files, the trigger can be set up as
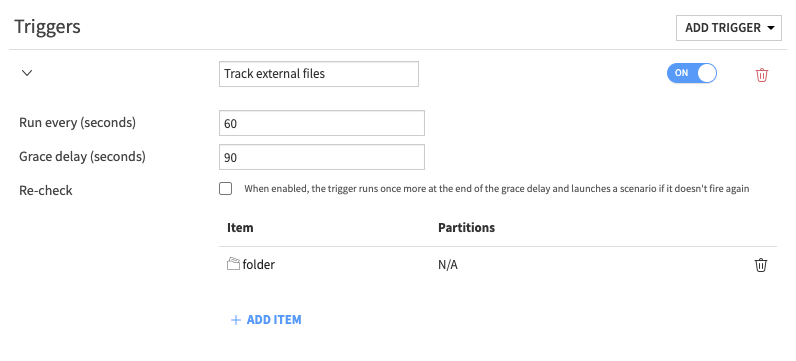
and the timeline is shrunk to
|
| - - uploading of file(s) starts
| <--- A: trigger evaluates to true, doesn't start a run
| ... 90s ...
| <--- scenario run starts (even if files are still being modified)
|
| <--- scenario run ends
|
Interaction between grace delays¶
The grace delay is defined independently on each trigger, so several triggers can be simultaneously pending, each one in its own grace delay. Additionally another trigger without grace delay can evaluate to true while some others are pending. The behavior in those cases is as such:
only the last trigger to exit its grace delay initiates a run
if a scenario run is started during the grace delay of a trigger, that trigger is cancelled
An example of a) is :
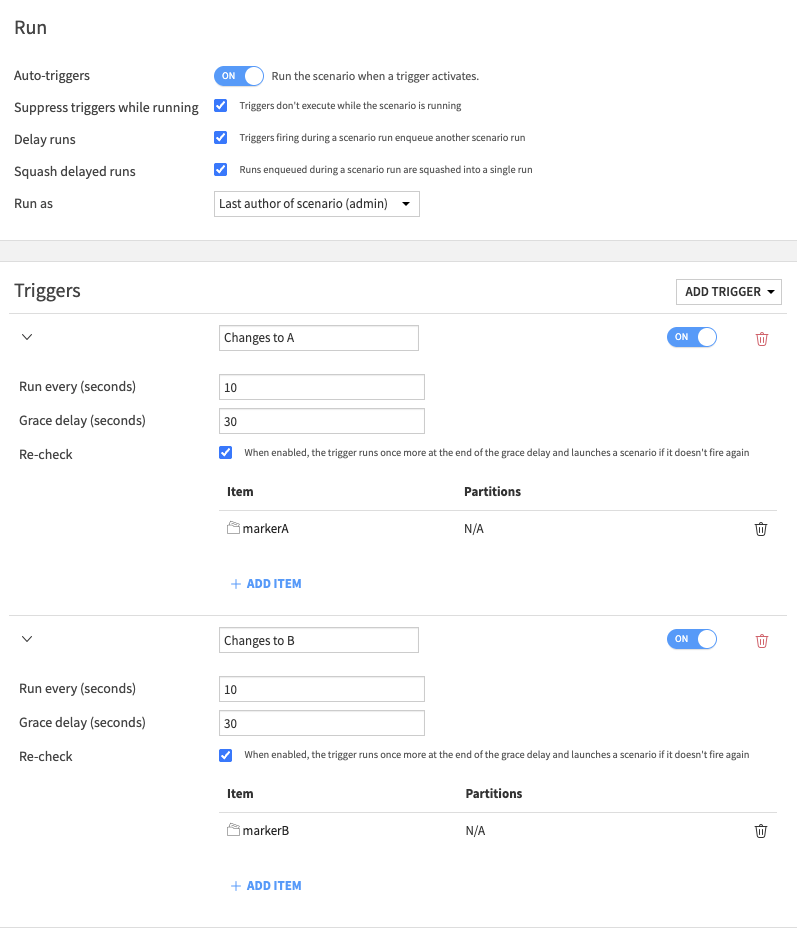
Then the triggers could run as follows:
|
| - - uploading of files in markerA starts
| <--- A: "Changes to A" evaluates to true, starts grace delay
| ... 30s ... files in markerA still being modified, files in markerB start changing
| <--- B: "Changes to A" evaluates to true, continues grace delay
| <--- C: "Changes to B" evaluates to true, starts grace delay
| ... 30s ... files in markerA stop changing, files in markerB still being modified
| <--- D: "Changes to A" evaluates to true, continues grace delay
| <--- E: "Changes to B" evaluates to true, continues grace delay
| ... 30s ... files in markerA not changing, files in markerB stop changing
| <--- F: "Changes to A" evaluates to false, exits grace delay, doesn't start a run
| <--- G: "Changes to B" evaluates to true, continues grace delay
| ... 30s ... files in markerA not changing, files in markerB not changing
| <--- H: "Changes to B" evaluates to false, starts a run
| <--- scenario run starts
|
| <--- scenario run ends
|
Here the event F doesn’t start a run of the scenario because another trigger than “Changes to A” has reset the scenario-wide grace delay. Only when that other trigger (here, “Changes to B”) exits its own grace delay is the run started.
An example of b) is :
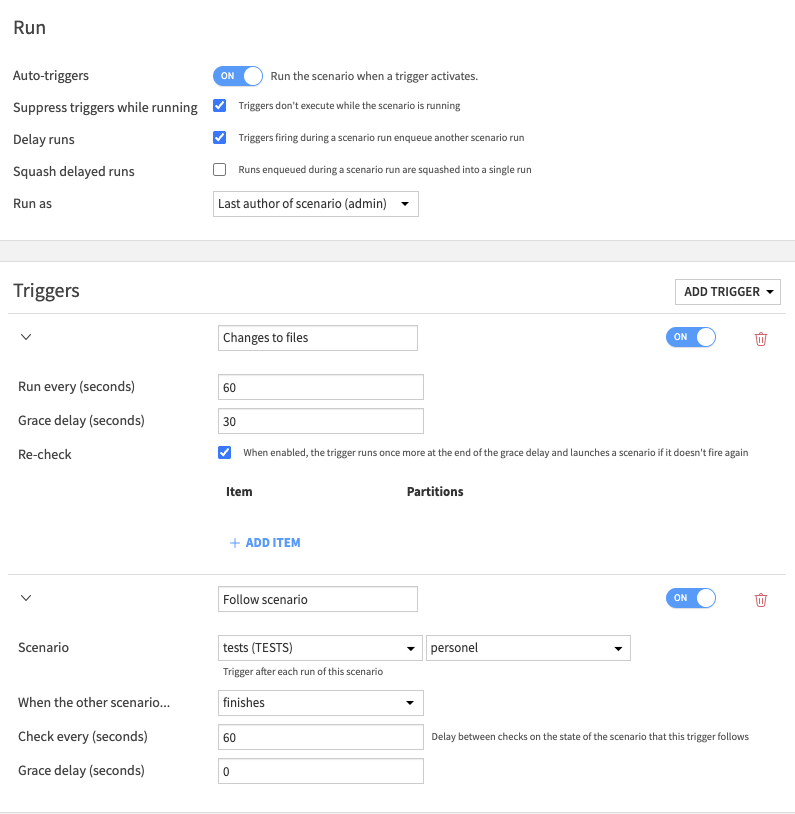
Then the triggers could run as follows:
|
| - - uploading of files starts
| <--- "Changes to files" evaluates to true, starts grace delay
| ... 30s ... files still being modified
| <--- "Changes to files" evaluates to true, continues grace delay
| ... 10s ... files stop changing
| <--- Follow scenario evaluates to true, start a run
| <--- scenario run starts
| ... 20s (remainder of grace delay)
| - - "Changes to files" isn't re-evaluated, and is cancelled
|
| <--- scenario run ends
|
In this setup, the “Changes to files” is completely cancelled, and there is no delayed run either, because the scenario suppresses trigger evaluations during runs.
Note
Time-based triggers have a fixed 2 seconds grace delay, without re-check. If two time-based triggers fire off within 2 seconds of each other, only the last one is kept.