
Deploying MLflow models¶
If your experiment tracking run logs a MLflow model (using the log_model function), it can be deployed directly from the UI.
Deploying a model¶
A model logged during an experiment tracking run may be deployed through the “Run details” screen, by clicking on the “Deploy” button in the models list.
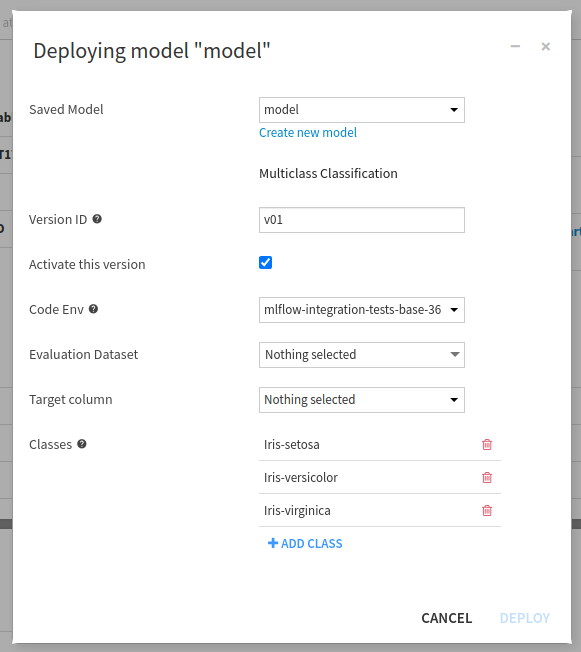
A regression or classification model deployed through the GUI is always evaluated on a dataset in order to provide a performance analysis. This is the same as models trained in DSS. To deploy a model without evaluating it, either set the prediction type to “Other” or use the API.
Note
The classes must be specified in the same order as learned by the model. If not, for a multi-class model for example, when the model outputs the probabilities, they will be in the wrong order.
The original experiment id and run id are automatically recorded when adding an MLflow model as a new version of a saved model.
Pre-defining the information for deployment¶
A lot of information that is not part of the MLflow model is required in order to deploy the MLflow model as a visual model in DSS. However, most of it can be pre-defined when the run is created, using a Dataiku extension to the MLflow API. This is especially handy when the model has many classes.
import dataiku
project = dataiku.api_client().get_default_project()
managed_folder = project.get_managed_folder('A_MANAGED_FOLDER_ID')
mlflow_extension = project.get_mlflow_extension()
with project.setup_mlflow(managed_folder=managed_folder) as mlflow_handle:
mlflow_handle.set_experiment("my_experiment")
with mlflow_handle.start_run(run_name="my_run") as run:
# ...your MLflow code...
# setting information to make the deployment of a model trained in this run easier through the GUI
# The classes must be specified in the same order as learned by the model.
classes = ['class_a','class_b','class_c']
# Some flavors such as scikit-learn may allow you to build this list from the model itself
classes = list(map(str, current_clf_model.classes_.tolist()))
mlflow_extension.set_run_inference_info(run._info.run_id, "MULTICLASS", classes,
"code_environment_name", "target_name")
These predefined parameters can be changed and overridden at deployment time except the model type.
Deploying through the API¶
A model can be deployed from an experiment tracking run using dataikuapi.dss.mlflow.DSSMLflowExtension.deploy_run_model().
Depending on the prediction type, the model will be evaluated during the deployment.
Most parameters are optional since dataikuapi.dss.mlflow.DSSMLflowExtension.deploy_run_model() will use by default what was set with dataikuapi.dss.mlflow.DSSMLflowExtension.set_run_inference_info().
mlflow_ext.set_run_inference_info(run.id, "BINARY_CLASSIFICATION", list_of_classes, code_env_name, target_column_name)
mlflow_extension.deploy_run_model(run.id, sm_id, evaluation_dataset)
Note
A model logged using the mlflow.log_model API is a MLflow model. As such, it can be also be imported using dataikuapi.dss.savedmodel.DSSSavedModel.import_mlflow_version_from_path() or dataikuapi.dss.savedmodel.DSSSavedModel.import_mlflow_version_from_managed_folder(). See Importing MLflow models.