
Sampling strategies for drift analysis¶
When computing drifts, using relevant data is key and, to that extent, defining the right sampling method is the most important aspect to understand well. Not using sampling is not a recommended approach as it will overload the execution, making it potentially very slow.
When dealing with sampling, a Model Evaluation will actually compare two datasets named ‘Reference’ and ‘Current’.
Definitions¶
Reference data
The reference dataset for model monitoring refers to the training data of the model. To be precise, we are using the test part of this training dataset. The way this test dataset is computed depends on your model design and can be entirely configured (you can learn more Settings: Train / Test set). This test dataset is defined when the model is trained and cannot be changed afterward. If you are not satisfied with its definition, you need to retrain a new model version with a new definition.
Current data
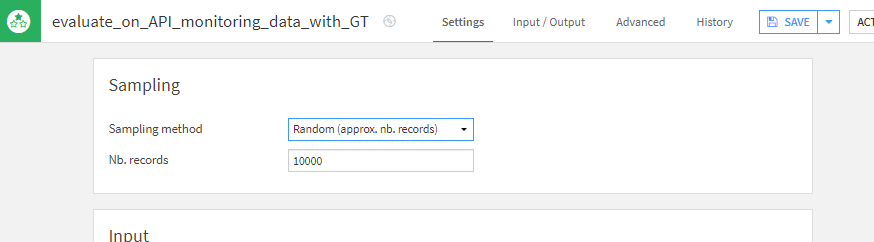
Each run of the Evaluate recipe will create one Model Evaluation containing all your drift metrics. The Current data is the content of the recipe’s input dataset when it runs. Dataiku offers the ability to define sampling rules for this dataset, defined in the Evaluate recipe, in the ‘Sampling’ section.
Note
There is an additional safety net for this sampling that will limit the result to 50k rows or 8Mb of compressed data. This can be removed in the Evaluate recipe advanced settings. It is important to note that this data is saved as part of the Model Evaluation, so removing this limit and using bigger sampling rules will lead to more disk space used, plan accordingly.
Data drift¶
Data drift will help you spot significant changes in the data distribution, not considering any specific Machine Learning aspect. In a Model evaluation, this will consider the reference dataset and the current dataset. If you read the section above, you know that reference dataset actually means the test part of your model training data and current means the input dataset content when the Evaluate recipe has been executed.
Note
You can also compute a pure data drift between any two dataset using a Standalone Evaluate Recipe.
Data drift in Dataiku actually computes 2 sets of metric: a global score and feature-by-feature score (also known as univariate drift). You can learn more about those metrics in Input Data Drift.
- Different rules are applied to compute those metrics:
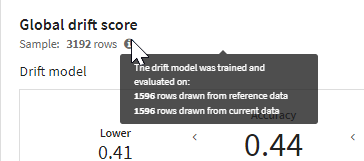
Global score: As we want to build a model to differentiate the reference and current datasets, we need to have balanced data, with the same number of rows from those two datasets. To do so, we count the number of rows from the smallest dataset and make a random sampling on the other to reduce it to the same number.
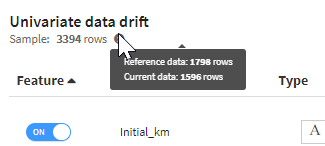
Univariate drift: Contrary to the global score, we do not care about imbalanced data so we will use as many rows as possible from both datasets
Prediction drift¶
Prediction drift is computed similarly to univariate data drift, so there is no sampling or filtering done on the reference or current dataset.
Performance drift¶
There is no additional sampling for this computation either: we compute the model performance metrics using all the current dataset rows.