
Prediction Overrides¶
Introduction¶
ML models today can achieve very high levels of performance and reliability but unfortunately this is not the general case, and often, they cannot be fully trusted for critical processes. There are many known reasons for this, including overfitting, incomplete training data, outdated models, differences between testing environment and real world…
Model overrides allow you to add an extra layer of human control over the models’ predictions, to ensure that they:
don’t predict outlandish values on critical systems,
comply with regulations,
enforce ethical boundaries.
By defining Overrides, you ensure that the model behaves in an expected manner under specific conditions.
Overrides are defined in Analysis > Modeling.
Overrides impact the predictions of the model. This notably affects:
the metrics of the model, computed after taking into account the defined overrides,
the predicted data, What-If analysis, individual prediction explanations, etc., and
all the data scored using a model with defined overrides, including via:
the Score and Evaluation recipes,
the API node,
an exported model.
Please note, however, that Hyperparameter Search is performed before the overrides are applied, so it does not take overrides into consideration.
Defining overrides¶
You can define multiple overrides on a given model. Each override consists of two parts:
a rule (if/when this happens), and
an outcome (then enforce this prediction).
The rule¶
The rule specifies the conditions to match against each row scored by the model. It can be defined by using either:
-

or the Dataiku Formula Language.
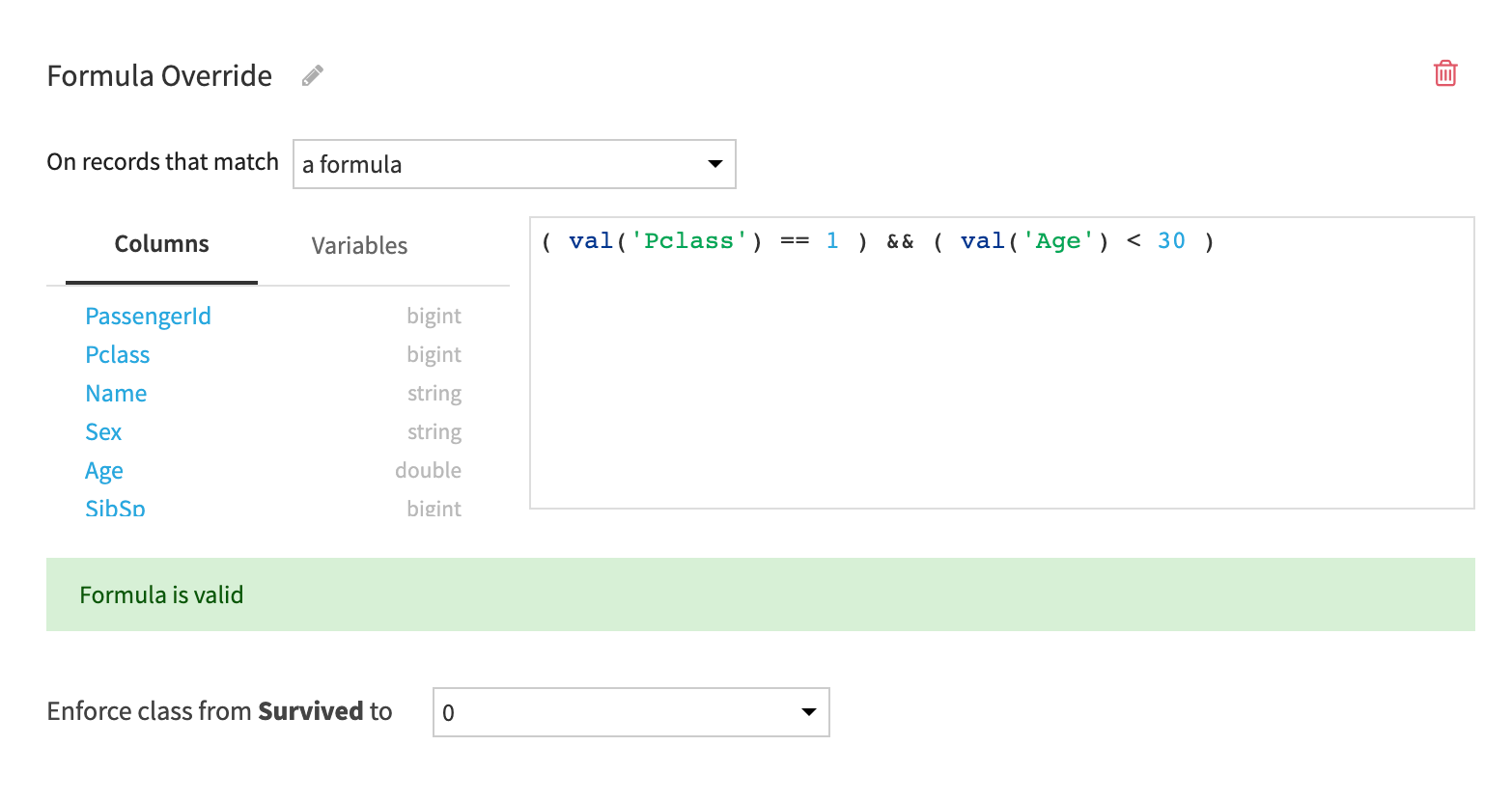
And the predicate can include both original dataset features and computed features like the prediction itself, the prediction intervals for regression models or the prediction uncertainty for classification tasks.
Warning
Overrides that use the Dataiku formula language are not compatible with Models Export.
The outcome¶
The outcome states how the prediction is overridden when the rule matches.
For classification tasks, the outcome is the class to predict when the rule matches.
For regression tasks, the outcome is a range of boundaries in which to clip the predicted value.
Note
When multiple overrides match a single row, only the first matching override applies.
Override Metrics¶
Information about overrides are available in the model’s results > Overrides.
It shows which rows matched with which override, alongside showing when the predictions were actually changed.
Note
A rule might match a row, but the model’s prediction may already be the same as it would be under the enforced outcome. In this case, the override is said to have applied but not changed the prediction.
For probabilistic classification models, note that the reported probabilities do change even when the prediction doesn’t.
Overrides Extra Info Column¶
When scoring with overrides, a column is added to the scored dataset with override information that shows the impact (or lack thereof) of overrides on each of the predictions. It is structured like so:
"override": {
"ruleMatched": true|false, # When false, this is the only field
"appliedRule": "Override 1"|null, # Name of the override that applied
"rawResult" : { # Original result before the override is applied
"prediction": "no", # Original prediction value
"probabilities": { # Original probabilities, only for classification models
"no": 0.95,
"yes": 0.05
}
},
"predictionChanged": true|false # True when the new prediction is different from the original
}
This column is added to:
the Predicted data tab in the model results,
the scored dataset, output of the scoring & evaluation recipes, and
the prediction response of Prediction Endpoint on the API node.
Limitations¶
Overrides are not available for:
tasks other than AutoML Prediction tasks (Deep learning, Clustering, Time series forecasting…),
backends other than the in-memory python backend (such as MLlib or H2O),
ensemble models, or
partitioned models.
Other limitations of Overrides:
Some Prediction Results such as Gini-based feature importance for tree models or regression coefficients, don’t consider overrides. Shapley feature importance and Individual prediction explanations do consider overrides.
Variables are not supported when defining override conditions (both visually or using formulas).
When using overrides, models can only be exported as Java, and only if they use visual rules.
For binary classification, the prediction cannot be used in the rule (match condition).
Python scoring on an API node is not supported when the model is using overrides, see Scoring engines.