Custom variables expansion¶
Variables expansion is a mechanism in DSS that allows you to use some shared and reusable variables in several parts of the Studio.
You can use variables:
Within the code of a code-based recipe
Directly in some configuration fields (for example, the path of a dataset)
For any field in the configuration of a dataset or a recipe using the override table mechanism.
In addition, you can write some custom Python code to automatically update the values of a variable.
Here are some use cases for variables expansion:
You have a fairly large flow and several recipes use a global “reference date”, for example the first date for when your data is available, or the last sales date. By putting this global date in a variable, you can update it in all recipes at once.
You have two DSS instances, one for development and one for production. You have partitioned datasets, and use the time range dependency to aggregate some data over periods. In development, you want your tests to be fast, so you only aggregate on 7 days, while in prod, you want to aggregate data on 365 days. By using environment-specific variables and an override on the partition dependency, you can achieve this easily.
Using variables in DSS is done in two steps:
Defining the variable and its value in the variables table
Referencing the variable using variable expansion syntax
Defining variables¶
Note
You can define variables in Admin tools > Administration, under Settings > Variables
All variables are defined in a JSON object. You are free to use anything as variable name, but we recommend that you stick to “regular” names: A-z, 0-9 and underscore.
{
"logs_preprocessing_excluded_ip": "194.254.61.161",
"logs_cumulative_aggregate_days": 7
}
Using variables in the code of a recipe¶
Variables can be substituted in the code of code-based recipes.
SQL¶
Variables are replaced in your code using the ${variable_name} syntax. For example:
SELECT * FROM logs WHERE ip != '${logs_preprocessing_excluded_ip}';
Hive¶
Variables are replaced in your code using the ${hiveconf:variable_name} syntax. For example:
SELECT * FROM logs WHERE ip != '${hiveconf:logs_preprocessing_excluded_ip}';
Note
In Hive, you must not quote the variable expansion for a string expansion
Python¶
All variables are available in a python dictionary retrieved by the dataiku.get_custom_variables()
function
So for example, you can use in your code:
import dataiku
print("I am excluding %s" % (dataiku.get_custom_variables()["logs_preprocessing_excluded_ip"]))
Note
This also works in the Python notebook
R¶
The value of a variable can be retrieved with the dkuCustomVariable(name) function.
So for example, you can use in your code:
library(dataiku)
dkuCustomVariable("logs_preprocessing_excluded_ip")
Note
This also works in the R notebook
Using variables in configuration fields¶
Some select configuration fields in the DSS interface can perform variables expansion using ${variable} syntax.
For example, you can use this in the Path field of Filesystem datasets

Note
For the specific case of Filesystem dataset paths, you can also select the prefix of a given Filesystem (or HDFS, S3, …) connection instead of using a variable.
Here, we use this when we want to move the dataset to the analysis of another company. Partitioning could be used here too.
The variables becomes very powerful when combined with dynamically updating the variables through code.
Using override tables¶
Some configuration fields can directly use variables expansion, but most can’t, especially when they do not store strings. However, you can override the value of any field in the configuration of a dataset or a recipe through an override table.
For example, we want to use a variable for the number of days aggregated in a Time range dimension.
In the recipe screen, this icon ![]() leads us to the override table:
leads us to the override table:
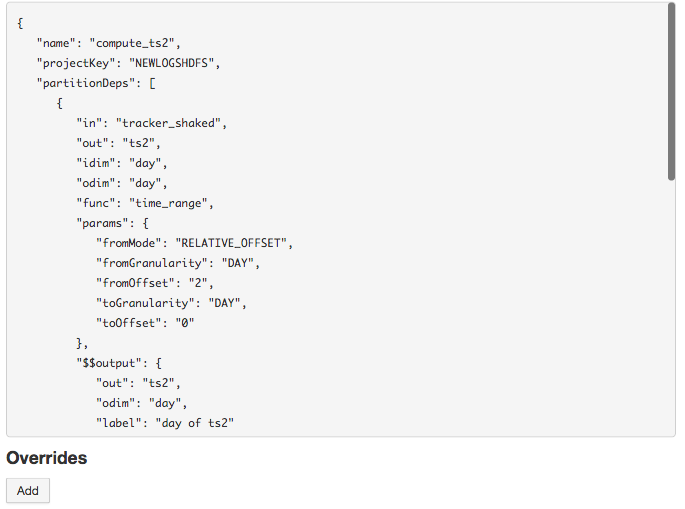
We see the JSON configuration of our recipe and we can now override any value. Here, we want to override the “fromOffset” value of the first partition dependency. Its “path” in the configuration is : partitionDeps[0].params.fromOffset.
So we add an override on this path
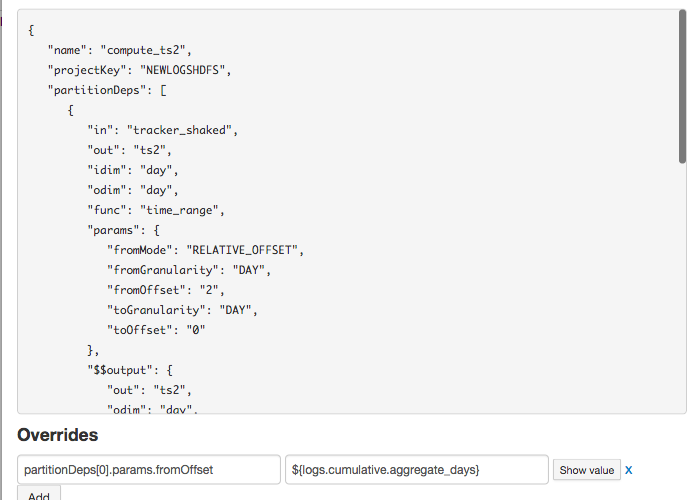
When we save and run the recipe, the “2” that was present gets overridden by the current value of the variable.
Warning
When using an override on a variable, the override is not visible in the interface itself. You still always see the non-overridden value (“2” in our case).
The override variables icon, however, turns red when an override is active.
Modifying the value of variables¶
In most cases, you will modify the values of variables from time to time, manually in the administration UI.
There are two other ways to modify the values of variables.
Environment-specific variables¶
The variables defined in the administration interface are store in the config/variables.json file.
In addition, if you create in your DSS DataDir a file named local/variables.json, the values in this file will override the values defined in the administration interface. This is a great way to have specific dev/prod settings, by copying the “config” folder but not the “local” folder.
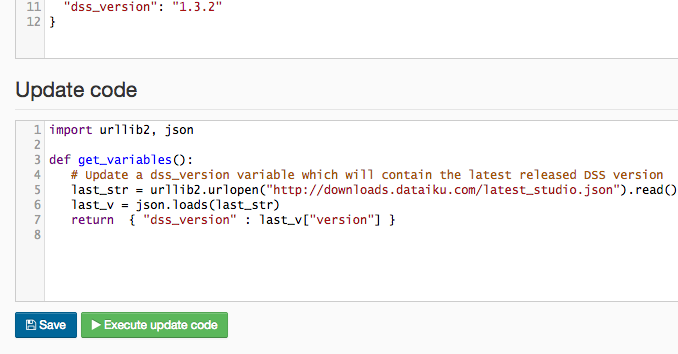
Update variables with code¶
You can write a snippet of Python code to compute the values of the variables. Your code runs:
Manually, when you click on the “Execute update” button in the Administration part
Automatically each time you start a job. The values computed by this are used only for this job
One important use case for this is integration with enterprise data catalogs. If you have a centralized service that is able to tell you the location of a given data source (and that location regularly changes), then it’s a good idea to put this location in a variable, and to write some code to update the value of this variable (by doing an API call to your centralized service).
Your code must contain a get_variables function that returns a Python dictionary. Each entry of the dictionary will become the value of one variable.