
Flow Document Generator¶
You can use the Flow Document Generator to create documentation associated with a project. It will generate on the fly a Microsoft Word™ .docx file that provides information regarding the following objects of the flow:
Datasets
Recipes
Managed Folders
Saved Models
Model Evaluation Stores
Labeling Tasks
Generate a flow document¶
Note
To use this feature, the graphical export library must be activated on your DSS instance. Please check with your administrator.
You can generate a document from a project with the following steps:
Go to the flow of the project
Click the
Flow Actionsbutton on the bottom-right cornerSelect
Export documentationOn the modal dialog, select the default template or upload your own template, and click
Exportto generate the documentAfter the document is generated, you will be able to download your generated document using the
Downloadlink
Custom templates¶
If you want the document generator to use your own template, you need to use Microsoft Word™ to create a .docx file.
You can create your base document as you would create a normal Word document
Sample templates¶
Instead of starting from scratch, you can modify the default template:
Placeholders¶
A placeholder is defined by a placeholder name inside two brackets, like {{project.name}}.
The generator will read the placeholder and replace it with the value retrieved from the project.
There are multiple types of placeholders, which can produce text, an image or a variable.
Conditional placeholders¶
You can customize even more your template by using conditional placeholders to display different information depending on the values of some placeholders
A conditional placeholder contains three elements, and each of them needs to be on a separate line:
a condition
a text to display if the condition is valid
a closing element
The condition itself is composed of three parts:
a text placeholder
an operator (
==or!=)a reference value
Example:
{{if my.placeholder == myReferenceValue }}
The placeholder is replaced by its value during document generation and compared to the reference value. If the condition is correct, the text is displayed, otherwise nothing will appear on the final document.
Note
To check if the value in the placeholder is empty, have a condition with no reference value.
Example:
{{if project.short_desc != }}
Project description: {{ project.short_desc }}
{{endif project.short_desc }}
Here is a more advanced example with a conditional boolean placeholders using a variable provided by an iterable placeholder. Boolean placeholders return the values “Yes” or “No” as text.
{{ if $recipe.is_code_recipe == Yes }}
Recipe code: {{ $recipe.payload }}
{{ endif $recipe.is_code_recipe }}
Iterable Placeholders¶
Iterable placeholders contain one or multiple objects and must be used with a foreach keyword, like this: {{ foreach $variableName in placeholder.name }}
(replace variableName with the name you want for your variable, and placeholder.name with the name of the placeholder).
Iterable placeholders provide a variable that can be used in other placeholders, depending on its type.
The type of the variable depends on the iterable placeholder that provided it.
see placeholder list.
Syntax rules:
A variable name must start with a
$and must not contain any..Iterable placeholders need to be closed with a
{{ endforeach $variableName }}
For example, the placeholder flow.datasets will iterate over all the datasets of the flow and
the variable it provides is of type $dataset so it can use all the placeholders starting with $dataset.
Here’s an example of how it can be used:
{{ foreach $d in flow.datasets }}
Dataset name: {{ $d.name }}
Dataset type: {{ $d.type }}
{{ endforeach $d }}
In this example, we iterate over all the datasets contained in the placeholder flow.datasets
and for each of these placeholders, we print the name and the type of the dataset.
It is possible to have an iterable placeholder inside another iterable. For example, to print the schema columns of all the datasets, you would do:
{{ foreach $dataset in flow.datasets }}
Dataset name: {{ $dataset.name }}
Dataset type: {{ $dataset.type }}
Schema:
{{ foreach $column in $dataset.schema.columns }}
Column name: {{ $column.name }}
Column type: {{ $column.type }}
{{ endforeach $column }}
{{ endforeach $dataset }}
Count placeholders¶
To know the number of elements in an iterable placeholder, use .count after the name of the iterable.
This can be useful when used with a conditional placeholder if you don’t want to display a section if there is no element. For example:
{{ if flow.models.count != 0 }}
Saved model section
There are {{ flow.models.count }} in the flow.
{{ foreach $model in flow.models }}
// Display model info
{{ endforeach $model }}
{{ endif flow.models.count }}
Type placeholders¶
To know the type of a variable, use .$type after the name of the variable.
This can be useful when used with a conditional placeholder if you want to display something different for a specific type in an iterable placeholder that can output multiple types.
See union-type iterable placeholders.
Union-types iterables¶
Some iterable placeholders can iterate over multiple types at the same time. For example, if you want to iterate over the outputs of a recipe, the type of the outputs can be datasets, managed folders, saved models or, model evaluation stores.
A variable created by an iterable placeholder with multiple output types can use all the placeholders common to the types it can be. The main flow objects (datasets, folders, recipes, models, labeling tasks and model evaluation stores) have at least these common placeholders:
id
name
creation.date
creation.user
last_modification.date
last_modification.user
short_desc
long_desc
tags
tags.list
If you want to use a placeholder specific to only one of the types, you need to use a conditional placeholder to check the type of the variable.
For example, to iterate over the outputs of a recipe:
{{ foreach $output in $recipe.outputs.all }}
Output name: {{ $output.name }}
Output description: {{ $output.short_desc }}
{{ if $output.$type = $dataset }}
// this placeholder would fail for other types, so it has to be used only for datasets
Dataset connection: {{ $output.connection }}
{{endif $output.$type }}
{{ endforeach $output }}
Note
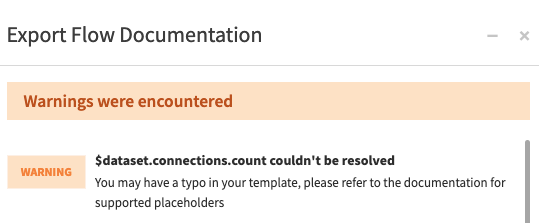
If there is a problem during the generation of the document, for example if a placeholder contains a typo, if a placeholder is used on a variable with the wrong type
or if there is no “end” placeholder after foreach or if placeholders, the placeholders will be removed in the final document
and there will be a warning displayed after the generation.
List of placeholders¶
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
config.author.email |
Text |
The email of the user running the Flow Document Generator |
config.author.name |
Text |
The user running the Flow Document Generator |
config.dss.version |
Text |
The version of the instance |
config.generation_date |
Text |
The date when the document is generated |
config.output_file.name |
Text |
The name of the document generated |
config.project.link |
Text |
A link to the project |
flow.datasets |
All datasets contained in this project |
|
flow.folders |
All managed folders contained in this project |
|
flow.labeling_tasks |
All labeling tasks in the project |
|
flow.model_evaluation_stores |
All model evaluation stores contained in the project |
|
flow.models |
All models contained in the project |
|
flow.picture.landscape |
Image |
A screenshot of the flow using landscape orientation. If the flow is too big to fit on one page, several pictures will be produced and inserted into the document. Each picture will be about as big as can fit on a single page. |
flow.picture.portrait |
Image |
A screenshot of the flow using portrait orientation. If the flow is too big to fit on one page, several pictures will be produced and inserted into the document. Each picture will be about as big as can fit on a single page. |
flow.recipes |
All recipes that are contained in the project. |
|
project.creation.date |
Text |
Creation date of the documented project |
project.creation.user |
Text |
The display name of the user who created the documented project |
project.current.git.branch |
Text |
The name of the currently active git branch of the documented project |
project.key |
Text |
The key of the documented project |
project.last_modification.date |
Text |
Date and time of the last modification of the documented project |
project.last_modification.user |
Text |
The display name of the user who last modified the documented project |
project.long_desc |
Text |
Long description of the documented project |
project.name |
Text |
The name of the documented project |
project.short_desc |
Text |
Short description of the documented project |
project.status |
Text |
The status of the documented project |
project.tags |
The list of tags associated with the documented project as an iterable placeholder (see project.tags.list for a simpler version) |
|
project.tags.list |
Text |
The list of tags associated with the documented project as a single string for simpler usage (all tags are concatenated, separated by commas - see project.tags for the iterable version) |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$chart.name |
Text |
Name of the chart |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$condition.description |
Text |
Returns a small description of the condition. |
$condition.left_column.name |
Text |
Returns the name of the first column in the condition |
$condition.right_column.name |
Text |
Returns the name of the second column in the condition |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$data_relationship.conditions |
Returns the list of join conditions linking the two datasets in data relationship. |
|
$data_relationship.left_dataset.name |
Text |
Returns the name of the left hand dataset in a data relationship. |
$data_relationship.left_dataset.participant_index |
Text |
Returns the index of the left hand dataset in the list of participants in data relationships, or ‘primary’ for the primary dataset (the same enrichment dataset can appear multiple times in the list with different indices, as part of different relationships). |
$data_relationship.left_dataset.time_index |
Text |
Returns the column name of the time index of the left hand dataset in a data relationship. |
$data_relationship.left_dataset.time_windows |
Returns the time windows related to the left hand dataset in a data relationship. |
|
$data_relationship.right_dataset.name |
Text |
Returns the name of the right hand dataset in a data relationship. |
$data_relationship.right_dataset.participant_index |
Text |
Returns the index of the right hand dataset in the list of participants in data relationships, or ‘primary’ for the primary dataset (the same enrichment dataset can appear multiple times in the list with different indices, as part of different relationships). |
$data_relationship.right_dataset.time_index |
Text |
Returns the column name of the time index of the right hand dataset in a data relationship. |
$data_relationship.right_dataset.time_windows |
Returns the time windows related to the right hand dataset in a data relationship. |
|
$data_relationship.type |
Text |
Returns the type of data relationship, such as ‘one-to-many’. |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$dataset.charts |
List of the charts associated with this dataset. For datasets shared between multiple projects, only the charts created in the current project are returned. |
|
$dataset.connection |
Text |
The name of the connection used for this dataset |
$dataset.containing.folder |
For ‘Files in Folder’ datasets, the folder that is the source of this dataset. It’s returned as an iterable with 1 element. For datasets that are not ‘Files in Folder’, or if the source folder is not in this project ($dataset is foreign), returns an iterable that contains 0 elements. |
|
$dataset.creation.date |
Text |
Creation date for the dataset |
$dataset.creation.user |
Text |
The display name of the user who created this dataset |
$dataset.data_steward |
Text |
The display name of the user set as Data Steward for the dataset, or None if no user was set. |
$dataset.full_name |
Text |
The full name of the dataset (includes the project key) |
$dataset.id |
Text |
Id of the documented dataset (without the project qualifier, yields the same result as $dataset.name) |
$dataset.is_foreign |
Text (Yes/No) |
Whether the dataset is foreign, eg if it belongs to another project but is exposed to this one. |
$dataset.is_partitioned |
Text (Yes/No) |
Whether the dataset is partitioned |
$dataset.last_modification.date |
Text |
The date of the last modification |
$dataset.last_modification.user |
Text |
The display name of the last modification author |
$dataset.long_desc |
Text |
The long description of the documented dataset |
$dataset.name |
Text |
The short name of the documented dataset (yields the same result as $dataset.id) |
$dataset.parent.all |
The parent of the current dataset. It’s returned as an iterable, that can contain 0 or 1 element. |
|
$dataset.parent.labeling_tasks |
The parent labeling task of the current dataset. It’s returned as an iterable, that can contain 0 or 1 element. |
|
$dataset.parent.recipes |
The parent recipe of the current dataset. It’s returned as an iterable, that can contain 0 or 1 element. |
|
$dataset.project.key |
Text |
The key of the project containing this dataset (mostly useful for foreign datasets, otherwise yields the same result as project.key) |
$dataset.project.name |
Text |
The name of the project containing this dataset (mostly useful for foreign datasets, otherwise yields the same result as project.name) |
$dataset.schema.columns |
Schema of the dataset, as a list of the schema columns. |
|
$dataset.short_desc |
Text |
The short description of the documented dataset |
$dataset.status.last_build |
Text |
Date and time of the last build. If no build is logged in the job database, ‘No build recorded’. |
$dataset.status.partition_count |
Text |
Last known number of partitions of the dataset. Using the placeholder will not trigger a computation as it can be long and expensive, so the value may be outdated if the dataset has changed since. If the size has never been computed, returns ‘Not computed’. If a recent value is required, it should be precomputed using the tools offered by DSS (metrics & scenarios). For non-partitioned datasets, returns 1. |
$dataset.status.record_count |
Text |
Last known number of records contained in the dataset. Using the placeholder will not trigger a computation as it can be long and expensive, so the value may be outdated if the dataset has changed since. If the size has never been computed, returns ‘Not computed’. If a recent value is required, it should be precomputed using the tools offered by DSS (metrics & scenarios). |
$dataset.status.total_size |
Text |
Last known size of the dataset files, if applicable. Using the placeholder will not trigger a computation as it can be long and expensive, so the value may be outdated if the dataset has changed since. If the size has never been computed, returns ‘Not computed’. If a recent value is required, it should be precomputed using the tools offered by DSS (metrics & scenarios). |
$dataset.successors.all |
The successors of the current dataset. It’s returned as an iterable, that can contain 0 or more elements. |
|
$dataset.successors.labeling_tasks |
The successor labeling tasks of the current dataset. It’s returned as an iterable, that can contain 0 or more elements. |
|
$dataset.successors.recipes |
The successor recipes of the current dataset. It’s returned as an iterable, that can contain 0 or more elements. |
|
$dataset.tags |
The list of tags associated with this dataset as an iterable placeholder (see $dataset.tags.list for a simpler version) |
|
$dataset.tags.list |
Text |
The list of tags associated with this dataset as a single string for simpler usage (all tags are concatenated, separated by commas - see $dataset.tags for the iterable version) |
$dataset.type |
Text |
The type of the documented dataset |
$dataset.worksheets |
List of the worksheets associated with this dataset. For datasets shared between multiple projects, only the worksheets created in the current project are returned. |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$file.last_modified |
Text |
The last modification date of a file. |
$file.path |
Text |
The path of a file relative to its containing managed folder. |
$file.size |
Text |
The size of a file |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$folder.connection |
Text |
The name of the connection used for this managed folder |
$folder.creation.date |
Text |
Creation date for the managed folder |
$folder.creation.user |
Text |
The display name of the user who created this managed folder |
$folder.files_in_folder.datasets |
The ‘Files in Folder’ datasets build from this folder. It’s returned as an iterable, that can contain 0 or more elements. |
|
$folder.files.list |
List all the files contained in the managed folder. Warning, this placeholder should be used with care because of the possible very high number of files contained in a managed folder, which could make this listing operation very long (and possibly costly depending on the managed folder location) |
|
$folder.full_id |
Text |
The full id of the documented managed folder (looks like PROJECTKEY.folderid) |
$folder.id |
Text |
Id of the documented managed folder (without the project qualifier) |
$folder.is_foreign |
Text (Yes/No) |
Whether the managed folder is foreign, eg if it belongs to another project but is exposed to this one. |
$folder.is_partitioned |
Text (Yes/No) |
Whether the managed folder is partitioned |
$folder.last_modification.date |
Text |
The date of the last modification |
$folder.last_modification.user |
Text |
The display name ofthe last modification author |
$folder.long_desc |
Text |
The long description of the documented managed folder |
$folder.name |
Text |
The short name of the documented managed folder |
$folder.parent.recipes |
The parent recipe of the current managed folder. It’s returned as an iterable, that can contain 0 or 1 element. |
|
$folder.project.key |
Text |
The key of the project containing this managed folder (mostly useful for foreign folders, otherwise yields the same result as project.key) |
$folder.project.name |
Text |
The name of the project containing this managed folder (mostly useful for foreign folders, otherwise yields the same result as project.name) |
$folder.short_desc |
Text |
The short description of the documented managed folder |
$folder.successors.all |
The successor of the current managed folder. It’s returned as an iterable, that can contain 0 or more elements. |
|
$folder.successors.labeling_tasks |
The successor labeling tasks of the current managed folder. It’s returned as an iterable, that can contain 0 or more elements. |
|
$folder.successors.recipes |
The successor recipes of the current managed folder. It’s returned as an iterable, that can contain 0 or more elements. |
|
$folder.tags |
The list of tags associated with this recipe as an iterable placeholder (see $folder.tags.list for a simpler version) |
|
$folder.tags.list |
Text |
The list of tags associated with this recipe as a single string for simpler usage (all tags are concatenated, separated by commas - see $folder.tags for the iterable version) |
$folder.type |
Text |
The type of the documented managed folder |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$join.condition_mode |
Text |
Returns the condition mode of the join (And, Or, Natural, Custom) |
$join.conditions |
Return the list of condition of the join. |
|
$join.left_dataset.name |
Text |
Returns the name of the first dataset in the join |
$join.right_dataset.name |
Text |
Returns the name of the second dataset in the join |
$join.type |
Text |
Returns the type of join (Inner, Outer, etc.) |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$labeling_task.creation.date |
Text |
Creation date of the labeling task |
$labeling_task.creation.user |
Text |
The display name ofthe user who created the labeling task |
$labeling_task.id |
Text |
Id of the labeling task (without the project qualifier) |
$labeling_task.inputs.all |
The list of all items that are used as input for this labeling task. The output has a mixed type, so you must be careful how it is used in order not to generate errors when generating a document on a complex flow (see union-type iterable placeholders for more details) |
|
$labeling_task.inputs.datasets |
The list of dataset that are used as input for this labeling task. The labeling task may have a folder as input, that is not listed here (see $labeling_task.inputs.folders or $labeling_task.inputs.all) |
|
$labeling_task.inputs.folders |
The list of managed folders that are used as input for this labeling task. The labeling task should have a dataset as input, that is not listed here (see $labeling_task.inputs.datasets or $labeling_task.inputs.all) |
|
$labeling_task.last_modification.date |
Text |
The date of the last modification |
$labeling_task.last_modification.user |
Text |
The display name ofthe last modification author |
$labeling_task.long_desc |
Text |
The long description of the labeling task |
$labeling_task.name |
Text |
Name of the labeling task |
$labeling_task.outputs.datasets |
The list of dataset used as output for this labeling task |
|
$labeling_task.short_desc |
Text |
The short description of the labeling task |
$labeling_task.tags |
The list of tags associated with this labeling task as an iterable placeholder (see $labeling_task.tags.list for a simpler version) |
|
$labeling_task.tags.list |
Text |
The list of tags associated with this labeling task as a single string for simpler usage (all tags are concatenated, separated by commas - see $labeling_task.tags for the iterable version) |
$labeling_task.type |
Text |
Type of the labeling task |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$model.active_version.name |
Text |
Name of the active version of the model |
$model.creation.date |
Text |
Creation date of the model |
$model.creation.user |
Text |
The display name ofthe user who created the model |
$model.id |
Text |
Id of the model (without the project qualifier) |
$model.is_foreign |
Text (Yes/No) |
Whether the model is foreign, e.g. if it belongs to another project but is exposed to this one |
$model.last_modification.date |
Text |
The date of the last modification |
$model.last_modification.user |
Text |
The display name ofthe last modification author |
$model.long_desc |
Text |
The long description of the documented model |
$model.name |
Text |
Name of the model |
$model.parent.recipes |
The parent recipe of the current model. It’s returned as an iterable, that can contain 0 or 1 element. |
|
$model.project.key |
Text |
The key of the project containing this model (mostly useful for foreign models, otherwise yields the same result as project.key) |
$model.project.name |
Text |
The name of the project containing this model (mostly useful for foreign models, otherwise yields the same result as project.name) |
$model.short_desc |
Text |
The short description of the documented model |
$model.successors.recipes |
The successor recipes of the current model. It’s returned as an iterable, that can contain 0 or more elements. |
|
$model.tags |
The list of tags associated with this model as an iterable placeholder (see $model.tags.list for a simpler version) |
|
$model.tags.list |
Text |
The list of tags associated with this model as a single string for simpler usage (all tags are concatenated, separated by commas - see $model.tags for the iterable version) |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$model_evaluation_store.creation.date |
Text |
Creation date of the model evaluation store |
$model_evaluation_store.creation.user |
Text |
The display name ofthe user who created the model evaluation store |
$model_evaluation_store.id |
Text |
Id of the model evaluation store (without the project qualifier) |
$model_evaluation_store.is_foreign |
Text (Yes/No) |
Whether the model evaluation store is foreign, e.g. if it belongs to another project but is exposed to this one |
$model_evaluation_store.last_modification.date |
Text |
The date of the last modification |
$model_evaluation_store.last_modification.user |
Text |
The display name ofthe last modification author |
$model_evaluation_store.long_desc |
Text |
The long description of the documented model evaluation store |
$model_evaluation_store.name |
Text |
Name of the model evaluation store |
$model_evaluation_store.parent.recipes |
The parent recipe of the current model evaluation store. It’s returned as an iterable, that can contain 0 or 1 element. |
|
$model_evaluation_store.project.key |
Text |
The key of the project containing this model evaluation store (mostly useful for foreign model evaluation stores, otherwise yields the same result as project.key) |
$model_evaluation_store.project.name |
Text |
The name of the project containing this model evaluation store (mostly useful for foreign model evaluation stores, otherwise yields the same result as project.name) |
$model_evaluation_store.short_desc |
Text |
The short description of the documented model evaluation store |
$model_evaluation_store.successors.recipes |
The successor recipes of the current model evaluation store. It’s returned as an iterable, that can contain 0 or more elements. |
|
$model_evaluation_store.tags |
The list of tags associated with this model evaluation store as an iterable placeholder (see $model_evaluation_store.tags.list for a simpler version) |
|
$model_evaluation_store.tags.list |
Text |
The list of tags associated with this model evaluation store as a single string for simpler usage (all tags are concatenated, separated by commas - see $model_evaluation_store.tags for the iterable version) |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$recipe.bottom_rows.count |
Text |
For Top N recipes, the number of bottom rows to keep |
$recipe.code_env |
Text |
For code recipes that use code env, return the code env used. See $recipe.has_code_env for an easy way to check if a given recipe has a code env. |
$recipe.creation.date |
Text |
Creation date for the recipe |
$recipe.creation.user |
Text |
The display name ofthe user who created this recipe |
$recipe.cutoff_time |
Text |
For a ‘Generate features’ recipe, returns the name of the column in the primary dataset used for the cutoff time (or an empty string if it was not set). Can only be used for a Generate features recipe, otherwise will issue a warning and output nothing. |
$recipe.data_relationships |
For a generate Features recipe, returns the list of data relationships. Can only be used for a ‘Generate features’ recipe, otherwise will issue a warning and output nothing. |
|
$recipe.distinct_keys |
Text |
For a Distinct recipe, returns the list of selected columns, as a string separated by ‘, ‘. Can only be used with a Distinct recipe, otherwise will issue a warning and output nothing. |
$recipe.feature_transformations.categorical |
Text |
For a ‘Generate features’ recipe, returns the active feature transformations of type ‘categorical’ (in the form of a string separated by ‘, ‘). Can only be used for a ‘Generate features’ recipe, otherwise will issue a warning and output nothing. |
$recipe.feature_transformations.date |
Text |
For a ‘Generate features’ recipe, returns the active feature transformations of type ‘date’ (in the form of a string separated by ‘, ‘). Can only be used for a ‘Generate features’ recipe, otherwise will issue a warning and output nothing. |
$recipe.feature_transformations.general |
Text |
For a ‘Generate features’ recipe, returns the active feature transformations of type ‘general’ (in the form of a string separated by ‘, ‘). Can only be used for a ‘Generate features’ recipe, otherwise will issue a warning and output nothing. |
$recipe.feature_transformations.numerical |
Text |
For a ‘Generate features’ recipe, returns the active feature transformations of type ‘numerical’ (in the form of a string separated by ‘, ‘). Can only be used for a ‘Generate features’ recipe, otherwise will issue a warning and output nothing. |
$recipe.feature_transformations.text |
Text |
For a ‘Generate features’ recipe, returns the active feature transformations of type ‘text’ (in the form of a string separated by ‘, ‘). Can only be used for a ‘Generate features’ recipe, otherwise will issue a warning and output nothing. |
$recipe.group_keys |
Text |
For a Grouping recipe, returns the list of group keys, as a string separated by ‘, ‘. Can only be used with a Grouping recipe, otherwise will issue a warning and output nothing. |
$recipe.has_code_env |
Text |
Indicates if the recipe has code env. |
$recipe.id |
Text |
Id of the documented recipe (without the project qualifier, yields the same result as $recipe.name) |
$recipe.inputs.all |
The list of all items that are used as input for this recipe. The output has a mixed type, so you must be careful how it is used in order to not generate errors when generating a document on a complex flow (see union-type iterable placeholders for more details) |
|
$recipe.inputs.datasets |
The list of datasets that are used as input for this recipe. The recipe may have other objects as input, that are not listed here (see $recipe.inputs.xxx) |
|
$recipe.inputs.folders |
The list of managed folders that are used as input for this recipe. The recipe may have other objects as input, that are not listed here (see $recipe.inputs.xxx) |
|
$recipe.inputs.model_evaluation_stores |
The list of model evaluation stores that are used as input for this recipe. The recipe may have other objects as input, that are not listed here (see $recipe.inputs.xxx) |
|
$recipe.inputs.models |
The list of saved models that are used as input for this recipe. The recipe may have other objects as input, that are not listed here (see $recipe.inputs.xxx) |
|
$recipe.is_code_recipe |
Text (Yes/No) |
Indicate if the recipe is a code recipe |
$recipe.is_filtered |
Text (Yes/No) |
For a Sample / filter recipe, indicates whether the filter option is enabled. Can only be used with a Sample / Filter recipe, otherwise will issue a warning and output nothing. |
$recipe.is_join |
Text (Yes/No) |
Indicates if the recipe is a join-like recipe (Join, Fuzzyjoin, Geojoin) |
$recipe.is_sampled |
Text (Yes/No) |
For a Sample / filter recipe, indicates whether the sample option is enabled (ie if the sample mode is not a full dataset). Can only be used with a Sample / Filter recipe, otherwise will issue a warning and output nothing. |
$recipe.joins |
For join-like recipes, returns the list of joins in the recipe. |
|
$recipe.last_modification.date |
Text |
The date of the last modification |
$recipe.last_modification.user |
Text |
The display name ofthe last modification author |
$recipe.left_unmatched_output.datasets |
For a join recipe, the left unmatched rows output dataset, if it exists. It’s returned as an iterable, that can contain 0 or 1 element. |
|
$recipe.left_unmatched_output.may_exist |
Text (Yes/No) |
For a join recipe, whether the join settings allow to save unmatched rows for the left dataset as a separate output |
$recipe.left_unmatched_output.name |
Text |
For a join recipe, the name of the left unmatched rows output dataset, if it exists |
$recipe.long_desc |
Text |
The long description of the documented recipe |
$recipe.name |
Text |
Name of the recipe (yields the same result as $recipe.id) |
$recipe.outputs.all |
The list of all items that are used as outputs of this recipe. The output has a mixed type, so you must be careful how it is used in order to not generate errors when generating a document on a complex flow (see union-type iterable placeholders for more details) |
|
$recipe.outputs.datasets |
The list of datasets that are used as outputs of this recipe. The recipe may have other objects as output, that are not listed here (see $recipe.outputs.xxx) |
|
$recipe.outputs.folders |
The list of managed folders that are used as outputs of this recipe. The recipe may have other objects as output, that are not listed here (see $recipe.outputs.xxx) |
|
$recipe.outputs.model_evaluation_stores |
The list of model evaluation stores that are used as outputs of this recipe. The recipe may have other objects as output, that are not listed here (see $recipe.outputs.xxx) |
|
$recipe.outputs.models |
The list of saved models that are used as outputs of this recipe. The recipe may have other objects as output, that are not listed here (see $recipe.outputs.xxx) |
|
$recipe.payload |
Text |
Returns the raw payload of the recipe. |
$recipe.pivots |
Text |
For Pivot recipe, returns a comma-separated list of the pivot columns |
$recipe.populated_columns |
Text |
For Pivot recipe, returns a comma-separated list of all the populated columns, only the name of the columns and the ‘Count of records’ are shown |
$recipe.prepare.steps |
For Prepare recipes, returns the list of steps of the recipe. |
|
$recipe.primary_dataset |
Text |
For a ‘Generate features’ recipe, returns the name of the primary dataset. Can only be used for a ‘Generate features’ recipe, otherwise will issue a warning and output nothing. |
$recipe.right_unmatched_output.datasets |
For a join recipe, the right unmatched rows output dataset, if it exists. It’s returned as an iterable, that can contain 0 or 1 element. |
|
$recipe.right_unmatched_output.may_exist |
Text (Yes/No) |
For a join recipe, whether the join settings allow to save unmatched rows for the right dataset as a separate output |
$recipe.right_unmatched_output.name |
Text |
For a join recipe, the name of the right unmatched rows output dataset, if it exists |
$recipe.row_identifiers |
Text |
For Pivot recipe, returns a comma-separated list of the row identifiers |
$recipe.short_desc |
Text |
The short description of the documented recipe |
$recipe.sorting_columns |
For Sort and Top N recipe, iterates over the sorted columns |
|
$recipe.split_mode |
Text |
For a Split recipe, returns a text explaining which rule is applied to split the input data. Can only be used with a Split recipe, otherwise will issue a warning and output nothing. |
$recipe.stack_mode |
Text |
For a Stack recipe, returns a text explaining which rule is applied to merge the schema of the input datasets. If the selected mode is to use the schema of one input dataset, its name will be indicated. Can only be used with a Stack recipe, otherwise will issue a warning and output nothing. |
$recipe.tags |
The list of tags associated with this recipe as an iterable placeholder (see $recipe.tags.list for a simpler version) |
|
$recipe.tags.list |
Text |
The list of tags associated with this recipe as a single string for simpler usage (all tags are concatenated, separated by commas - see $recipe.tags for the iterable version) |
$recipe.top_rows.count |
Text |
For Top N recipes, the number of top rows to keep |
$recipe.type |
Text |
Type of the recipe, as displayed by the UI. |
$recipe.unique_keys |
Text |
For a Push to Editable recipe, returns the list of columns used to identify the lines (unique keys in the UI), as a string separated by ‘, ‘. Can only be used with a Push to Editable recipe, otherwise will issue a warning and output nothing. |
$recipe.windows |
For Window recipes, iterate over the windows of the recipe. |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$schema_column.description |
Text |
Description of the column |
$schema_column.name |
Text |
Name of the column |
$schema_column.type |
Text |
Storage type of the column |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$sorted_column.direction |
Text (Ascending/Descending) |
The direction of the sort (Ascending or Descending) |
$sorted_column.name |
Text |
The name of the column |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$step.comment |
Text |
Returns the comment of the step, if there is one. |
$step.type |
Text |
Returns the type of the step. |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$tag.name |
Text |
The name of a tag |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$time_window.from |
Text |
Returns the starting point of the interval in a time window (in the number of multiples of the unit prior to the cutoff time). |
$time_window.to |
Text |
Returns the end point of the interval in a time window (the number of multiples of the unit prior to the cutoff time). |
$time_window.units |
Text |
Returns the units used in the time window, in pluralized form, e.g. ‘days’. |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$window.name |
Text |
The name of the window |
$window.partitioning_columns |
Text |
Comma-separated list of the partitioning columns of the window |
Placeholder name |
Output type |
Description / prerequisite |
|---|---|---|
$worksheet.name |
Text |
Name of the worksheet |