
SQL recipes¶
For introduction information about SQL datasets, please see SQL databases
DSS allows you to build datasets by executing SQL statements. Two variants are provided :
The “SQL query” recipe
The “SQL script” recipe
Note
The SQL query recipe is the simplest recipe. Its usage should generally be preferred.
SQL “query” recipe |
SQL “script” recipe |
|
|---|---|---|
Purpose |
The SQL query should generally be preferred. It allows you to focus on writing your query, while leaving plumbing work to DSS. |
The “SQL script” recipe should be used in the few cases where DSS cannot rewrite your query from a main SELECT statement. Two prominent examples are, the CTE (“WITH”) construct and data types not handled by DSS directly (like Geometry datatypes). |
Structure |
At its core, a SQL query recipe is a SELECT statement. DSS reads the results from this SELECT statement and handles the task of writing the data to the output. The query can also include other statements that are executed before and after the main SELECT. (see below) |
A SQL script recipe is a complete SQL script, made of several statements. DSS simply asks the database to execute the statement, and does not rewrite it. |
In / Out |
|
|
Features |
|
|
Limitations |
|
|
SQL query recipe¶
To write a SQL query recipe :
Create the recipe, either from the “New recipe” menu, or using the Actions menu of a dataset.
Select the input dataset(s). All input datasets must be SQL table datasets (either external or managed), and they generally must all be in the same database connection (if not, see Using multiple connections).
Select or create the output dataset.
Save and start writing your SQL query. Your query must consist of a top-level SELECT statement (plus optional other statements, see below)
Note
You cannot write a SQL recipe based on a “SQL query” dataset. Only “SQL table” datasets are supported.
Testing and schema handling¶
At any point, you can click the Validate button. This does the following :
Check that the query is valid (syntactically and grammatically)
Fetch the names and types of columns created by the query
Compare them to the schema of the output dataset.
If the schemas don’t match (which will always be the case when you validate for the first time), DSS will explain the incompatibilities and propose to automatically adjust the output dataset schema. You also get details if there is a discrepancy.
If you overwrite the output schema while the output already contains data, it is strongly recommended to drop the existing data (and, if the output is SQL, drop the existing table). Not dropping the data would make the pre-existing data (and/or table) inconsistent with the schema of the output dataset as recorded by DSS, leading to various issues.
Note
The Validate button does not execute the query, it only asks the database to parse it. As such, executions of the validation step are always cheap, whatever the complexity of the query and size of the database.
Creating tables¶
In a SQL query recipe, DSS automatically creates the output tables, and automatically handles clearing them or dropping them before running the recipe. You do not have anything to handle manually.
Previewing results¶
Near the Validate button is a “Display first rows” button. Clicking it executes the query and displays the first rows. If the query is complex, this test can be costly.
You might also want to use a SQL notebook to work on your query.
Execution plan¶
Near the Validate button is a “Execution plan” button. Clicking it asks the database to compute the execution plan and displays it. This is useful to evaluate whether your recipe works as expected.
Execution method¶
When the output dataset is a SQL table and is in the same connection as the input datasets, DSS will execute the query fully in the target database. DSS automatically rewrites your SELECT query to a “INSERT INTO … SELECT”.
In other cases, DSS will stream the SELECT results from the source database to the DSS server and write them back in the target.
Using multiple connections¶
By default, in a SQL query recipe, all the inputs must be in the same database connection and, if needed, the output can be in another one (in this case the results are streamed through DSS).
You can explicitly enable an option to support inputs in multiple connections but this will only work if all the inputs can be accessed from the main SQL connection. To do so, go to the Advanced settings of the recipe, check the Allow SQL across connections option and pick the connection where the query will be executed.
The same option can be used to execute the query in the output connection, so that the results are not streamed through DSS but directly in-database.
Note
When using this option, you are responsible for making sure that all the inputs can be accessed from the selected connection.
In your query, you may need to use fully qualified names with explicit catalog and schema names, e.g. when using connections with different default schemas, or for cross-database setups.
Multiple statements handling¶
In a SQL query recipe, the “core” of your code is a SELECT statement that DSS uses to stream the results (or insert them into the target table). Access to this SELECT statement is also used by DSS to compute the schema of the output dataset.
However, you can also write statements before and after the main SELECT.
Use cases for this include:
Pre statements that create temporary tables, used by the main SELECT
Pre statements creates indexes, post statements drop them
Pre statements define a temporary stored procedure
Since DSS needs to isolate the main SELECT statement to fetch the results from it, DSS splits your code in multiple statements, and considers the last SELECT statement found in your code as the “main” SELECT.
DSS splits statement with a logic that recognizes most semantic constructs. It supports comments, various kinds of quoting, …
However, DSS does not have full SQL parsing capability (which would be specific to each kind of database). Some constructs will confuse the splitter. For example, definition of stored procedures, if not quoted, will generally be improperly split. To work around this, you can take control over the splitting by inserting -- DKU_END_STATEMENT between each statement. If your code contains this -- DKU_END_STATEMENT constructs, then the DSS automatic splitter will be disabled.
For example, the following code would be improperly split by DSS, since it does not recognize that it’s in a stored procedure.
CREATE PROCEDURE myproc1 (IN a int)
BEGIN
IF a > 42;
INSERT INTO mytable values (a);
END IF;
END;
CALL myproc1(17);
SELECT * from mytable;
Instead, write:
CREATE PROCEDURE myproc1 (IN a int)
BEGIN
IF a > 42;
INSERT INTO mytable values (a);
END IF;
END;
-- DKU_END_STATEMENT
CALL myproc1(17);
-- DKU_END_STATEMENT
SELECT * from mytable;
Limitations of the SQL query recipe¶
On a SQL query recipe, DSS needs to rewrite the query to transform a SELECT into an INSERT. This is required so that DSS can still read the schema of your query.
The DSS logic to rewrite query supports a variety of SQL constructs, including subqueries and UNION queries.
However, some advanced SQL constructs require a level of parsing that DSS does not have, and cannot be properly rewritten as INSERT. In that case, you will see parsing errors when executing your SQL query recipe.
A prominent of this is the “Common Table Expression” (CTE) construct, ie. the “WITH” statement:
WITH s1 AS
(select col, count(*) as cnt from A group by col)
SELECT B.*, s1.cnt
from B
inner join s1
on s1.col = B.col;
DSS is not able to properly insert the INSERT at the right location in this kind of queries. We suggest that you either:
Rewrite the query not to use a CTE (but this might prove impossible if you use the recursive capabilities of CTEs)
Use a SQL script recipe as detailed below.
SQL Script recipe¶
To write a SQL script recipe:
Create the recipe, either from the “New recipe” menu, or using the Actions menu of a dataset.
Select the input dataset(s). All input datasets must be SQL table datasets (either external or managed), and must all be in the same database connection.
Select or create the output dataset(s). All output datasets must be SQL table datasets and they generally must all be in the same database connection as the input datasets (if not, see Using multiple connections)
Save and start writing your SQL script. The script must perform the insertions in the output tables. It may also handle creating and dropping the output tables.
In a SQL script recipe, DSS can not perform the same level of query analysis as in a SQL query recipe. Therefore, there is no “display first rows” button and the “validate” button only checks the validity of the configuration.
Only running the recipe will actually execute the SQL script.
Recipes in DSS should generally be idempotent (i.e., running them several times should not impact the results). Therefore, you should always have a TRUNCATE or DELETE statement in your SQL script.
Note
The previous statement does not apply exactly this way for partitioned SQL recipes. See Partitioned SQL recipes for more details.
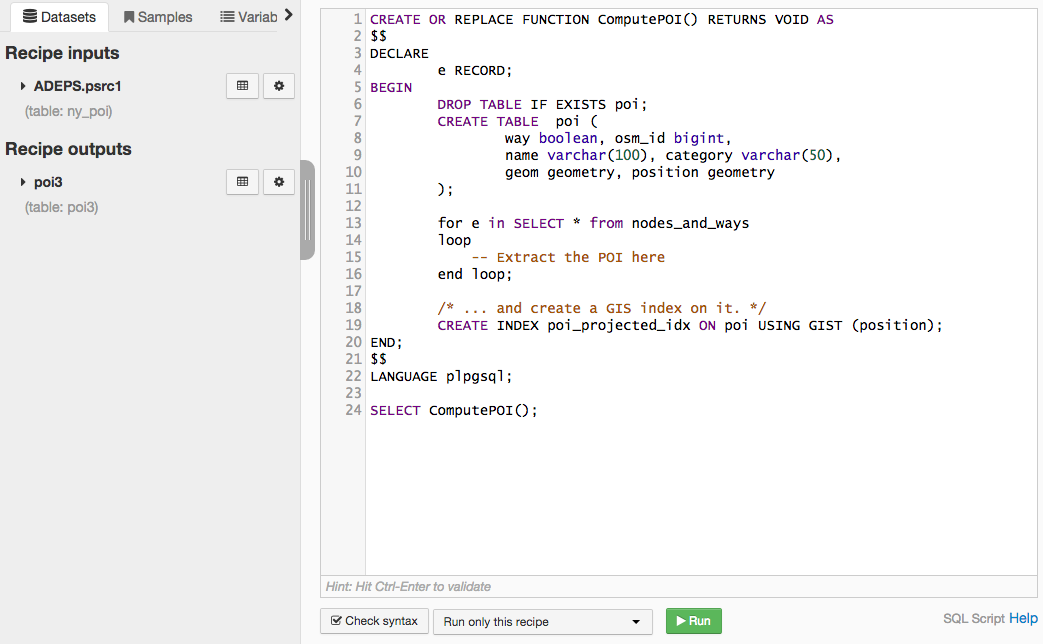
Use cases for SQL scripts¶
The main use cases for using a SQL script are:
When you manipulate a data type which is not natively handled by DSS. For instance, the PostGIS geometry types. Using SQL query, DSS would write as “varchar” the output columns, losing the ability to perform geo manipulation.
The Common Table Expression (CTE), aka the “WITH” statement, is generally not properly handled in a SQL query recipe.
When you need multiple outputs in a single SQL recipe.
When you need UPDATE or MERGE statements rather than INSERT.
Note
If you need to use stored procedures or temporary tables, the SQL query recipe generally fulfills your need since you can use multiple statements in a SQL query recipe.
Managing schema or creating tables¶
In a SQL script recipe, DSS cannot detect the output schema of the output datasets. Detecting the schema is done at the end of the recipe: DSS asks the database for the metadata from the tables that your script created and then fills in the schema of the dataset.
This automatic filling of the schema from the table can be disabled in the Advanced settings of the SQL script recipe. In that case, after running the script, the schema of the dataset will be empty, while the table will have a non-empty schema. When you go to the explore of the output dataset(s), DSS will emit an error because the schema of the dataset does not match the table. To fix this, go to the settings of the output dataset(s), and click “Reload schema from table”. DSS fills the schema of the dataset, which is now consistent.
Another possible way is to start by writing manually the schema before running the SQL script. However, manually writing the schema for a non trivial table is a very cumbersome task.
Modification of the schema¶
Since the SQL script recipe cannot detect the schema without running, if you modify the code of a SQL script recipe to generate a differently-shaped table, don’t forget that you actually need to run the SQL script recipe so that the new schema of the dataset becomes effective and can be used in a further Flow step.
This behavior is similar to the behavior of Python and R recipes, but different from the behavior of SQL query recipe where a simple Validate can update the schema, without the need to actually run the recipe.
Using multiple connections¶
By default, in a SQL script recipe, all the inputs and outputs must be in the same database connection.
You can explicitly enable an option to support datasets in multiple connections but this will only work if all the inputs and outputs can be accessed from the main SQL connection. To do so, go to the Advanced settings of the recipe, check the Allow SQL across connections option and pick the connection where the query will be executed.
Note
When using this option, you are responsible for making sure that all the inputs and outputs can be accessed from the selected connection.
In your query, you may need to use fully qualified names with explicit catalog and schema names, e.g. when using connections with different default schemas, or for cross-database setups.
Multiple statements handling¶
See the paragraph about multiple statements handling in the SQL query recipe. Same rules apply to SQL script recipe.
PostgreSQL-specific note¶
By default, SQL script recipes on PostgreSQL are run using the psql client tool. Using psql has the main advantage that the common RAISE NOTICE statements used for progress tracking in very long-running queries will be displayed in the log of the job as soon as they happen. However, this needs psql to be installed.
You can either:
Tell DSS not to use psql for a given SQL script recipe (go to the Advanced tab of the recipe editor)
Ensure that psql is installed and in your PATH.
Beware, on some Linux distributions or on some macOS package managers, installing the postgresql package does not place psql in PATH, but instead place it in a non-standard location, or with a non-standard name. You will need to ensure that a binary called psql is in your PATH, either by modifying the PATH of DSS or by adding wrapper scripts.