Sampling¶
When exploring and preparing data in DSS, you always get immediate visual feedback, no matter how big the dataset that you are manipulating. To achieve this, DSS works on a sample of your dataset.
Sampling in Explore¶
By default, the first 10,000 records of your dataset are selected for the sample. While this sampling method does not provide the best sample quality, it allows you to get your sample very quickly, whatever the size of your dataset.
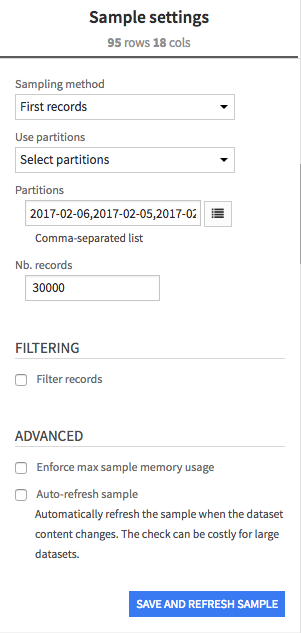
The sampling can be configured in the “Sampling” tab
Warning
For best performance in interactive exploration, the sample is always loaded in RAM. It is therefore crucial that you do not configure a sample so large that it would not fit in the memory of the Data Science Studio backend.
For best performance, it is recommended that you do not use samples above 200 000 records.
For more information about raising the backend memory limit, see Tuning and controlling memory usage
Sampling methods¶
DSS provides many sampling methods for exploration and data preparation.
Note
There are other parts of DSS where sampling can be applied:
Charts
Sampling recipe
Machine learning
API
Not all sampling methods are available in the different locations. Exploration / data preparation have the most available sampling methods, thanks to the fact that the output of the sampling for exploration and data preparation must always fit in memory.
First records¶
This sampling method simply takes the first N rows of the dataset. If the dataset is made of several files, the files will be taken one by one, until the defined number of records is reached for the sample.
This method is by far the fastest sampling method, as only the first records need to be read from the dataset. However, depending on how your data is organized in the dataset, it can provide a very biased view of the dataset.
Random sampling (fixed number of records)¶
This method randomly selects N records within the whole dataset. This method requires a full pass reading the data. The time taken by this method is thus linear with the size of the dataset.
Random sampling (approximate ratio)¶
This method randomly selects approximately X% of the records. This method requires a full pass reading the data. The time taken by this method is thus linear with the size of the dataset.
Beware that if you have a very large dataset, this could lead to extremely high sample sizes.
Column values subset¶
This method randomly selects a subset of values and chooses all rows with these values, in order to obtain approximately N rows. This is useful for selecting a subset of customers, for example.
This sampling method requires 2 full passes reading the data. The time taken by this method is thus linear with the size of the dataset.
This method is useful if you want to have all records for some values of the column, for your analysis. For example, if your dataset is a log of user actions, it is more interesting to have “all actions for a sample of the users” rather than “a sample of all actions”, as it allows you to really study the sequences of actions of these users.
“Column values subset” sampling will only provide interesting results if the selected column has a sufficiently large number of values. A user id would generally be a good choice for the sampling column.
Stratified (fixed number of records)¶
This method randomly selects N rows, ensuring that the distribution of values in a column is respected in the sampling. Ensures that all values of the column appear in the output.
This method may return a few more than N rows.
This sampling method requires 2 full passes reading the data. The time taken by this method is thus linear with the size of the dataset.
Stratified (approximate ratio)¶
This method randomly selects X% of the rows, ensuring that the distribution of values in a column is respected in the sampling. Ensures that all values of the column appear in the output.
This method may return a bit more than X% rows.
This sampling method requires 2 full passes reading the data. The time taken by this method is thus linear with the size of the dataset.
Class rebalancing (approximate number of records)¶
This method randomly selects approximately N rows, trying to rebalance equally all modalities of a column. This method does not oversample, only undersample (so some rare modalities may remain under-represented).In all cases, rebalancing is approximative.
This sampling method requires 2 full passes reading the data. The time taken by this method is thus linear with the size of the dataset.
Class rebalancing (approximate ratio)¶
This method randomly selects approximately X% of the rows, trying to rebalance equally all modalities of a column.
This method does not oversample, only undersample (so some rare modalities may remain under-represented). In all cases, rebalancing is approximative.
This sampling method requires 2 full passes reading the data. The time taken by this method is thus linear with the size of the dataset.
Last records¶
This method takes the last N rows of the dataset.
This method requires a full pass reading the data. The time taken by this method is thus linear with the size of the dataset.
Sampling and partitioning¶
If the dataset is partitioned, by default, DSS will use all partitions to compute the sample. You can also explicitly select some of the partitions.
Selected partitions can be entered manually.
Or you can click the « Retrieve list » button to select a subset of the partitions currently detected in the dataset:
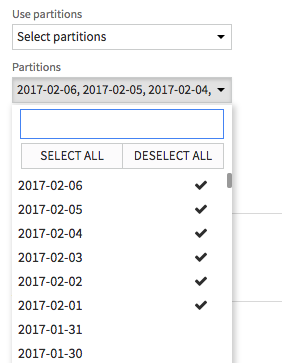
Note
Listing all partitions in the dataset can be slow, especially for SQL datasets
Refreshing the sample¶
The first time you open a dataset in Explore, the sample will be computed according to the default sampling parameters. Once a sample has been computed, Data Science Studio will not recompute each time, but reuse it.
The sample is recomputed to take into account new data in the following cases :
If the dataset is a managed dataset and has been rebuilt since the sample was computed. For more information about managed datasets and building datasets, see DSS concepts
If the configuration of the dataset has been changed in the « Configure dataset » screen.
If the sampling configuration is changed
At any time, you can also open the Sampling configuration box and click the “Save and Refresh Sample” button to recompute the sample.
In addition, for some kinds of datasets, you can ask DSS to automatically recompute the sample each time the content of the dataset changes. This is NOT possible for SQL-based datasets. Note that checking if the dataset content changed can be slow for very large files-based datasets, as Data Science Studio needs to enumerate all files (especially for S3 datasets).